UiPath Blog

Summarize:
はじめに
初めまして。UiPath の Liu です。
本記事では、UiPath に従来から組み込まれている OCR アクティビティと、v2019 ファストトラックの一部としてリリースされた UiPath 独自の AI-OCR 機能を提供する「ドキュメント処理プラットフォーム」を紹介します。
UiPath における OCR 手段
UiPath のロボットに OCR を行わせる手段は大きく2つに分かれます。
手段1.外部の OCR アプリケーションとの連携
UiPath ロボットが外部の OCR アプリケーションとデータをファイルや API でやりとりする手段です。
典型的な処理の流れとしては次のようになります:① UiPath ロボットが処理対象の帳票ファイルを外部の OCR アプリケーションに送信、② OCR アプリケーションが OCR 処理結果を CSV ファイルなどとして出力、③ UiPath ロボットが OCR 処理結果の CSV ファイルを取得し、他の Web アプリケーションなどに入力。
手段2.UiPath 組み込みの OCR アクティビティの利用
UiPath ロボットが内部の処理として OCR アクティビティを通じて OCR エンジンを呼び出して、一連の自動化を行う手段です。
UiPath では画面領域に対して OCR を行う「OCR でテキストを取得」アクティビティや、PDF ファイルを読み込んで OCR を行う「Read PDF With OCR」アクティビティなど様々なアクティビティを用意しています。使用するエンジンは後述するいくつかの種類から選択することが可能です。
上記の OCR アクティビティ群は様々な OCR 機能を提供しますが、手段1.に比べて紙帳票を読み取るという目的に特化していないため、実際の業務自動化では使いにくいという課題がありました。
一方、v2019 ファストトラックの一部としてリリースされた UiPath の提供する「ドキュメント処理プラットフォーム」は、組み込みの OCR アクティビティでありながら AI-OCR による高度な紙帳票の読み取り業務を自動化することが可能です。
以下では手段2.について詳しく見ていきましょう。
UiPath 組み込みの OCR アクティビティ一覧
まず、v2019 ファストトラックまでリリースした UiPath 組み込みの OCR アクティビティを紹介します。
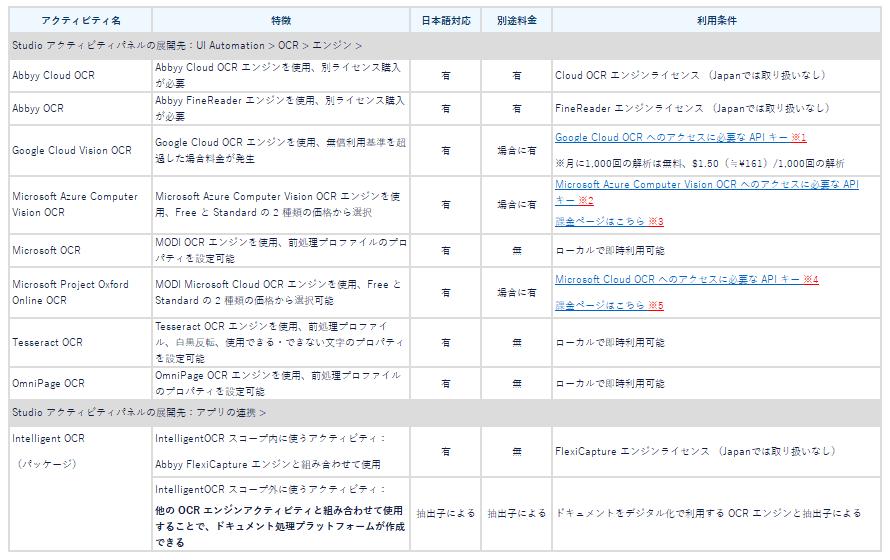
※1 Google Cloud OCR へのアクセスに必要な API キー
※2 Vision OCR へのアクセスに必要な API キー
※3 課金ページはこちら
※4 Microsoft Cloud OCR へのアクセスに必要な API キー
※5 課金ページはこちら
UiPath のドキュメント処理プラットフォーム
次は UiPath 組み込みの OCR アクティビティを利用するドキュメント処理プラットフォームを紹介します。
UiPath のドキュメント処理プラットフォームの一般的なフローは下記の図で表せます。
※このフロー図にある「タクソノミーをロード」、「検証ステーションを提示」などのアクティビティを利用するには、v1.6.0 以上の UiPath.IntelligentOCR.Activities パッケージが必要です。
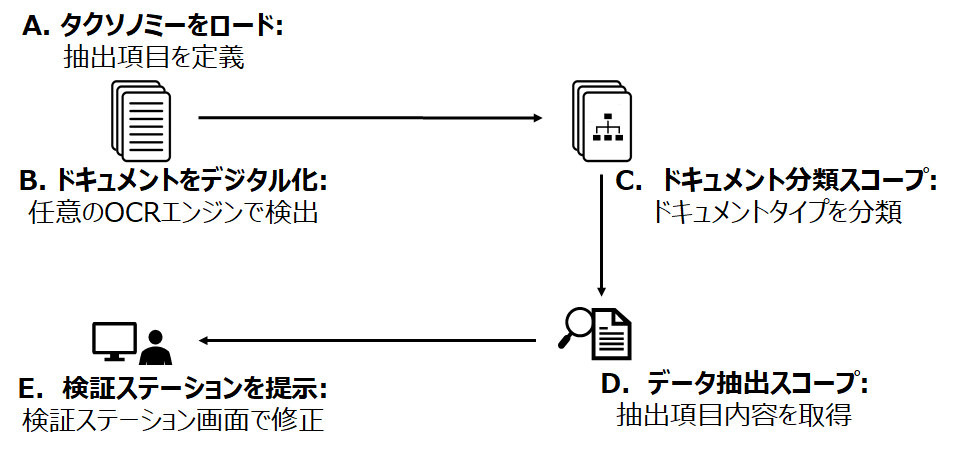
ドキュメント処理の主要ステップを説明します。
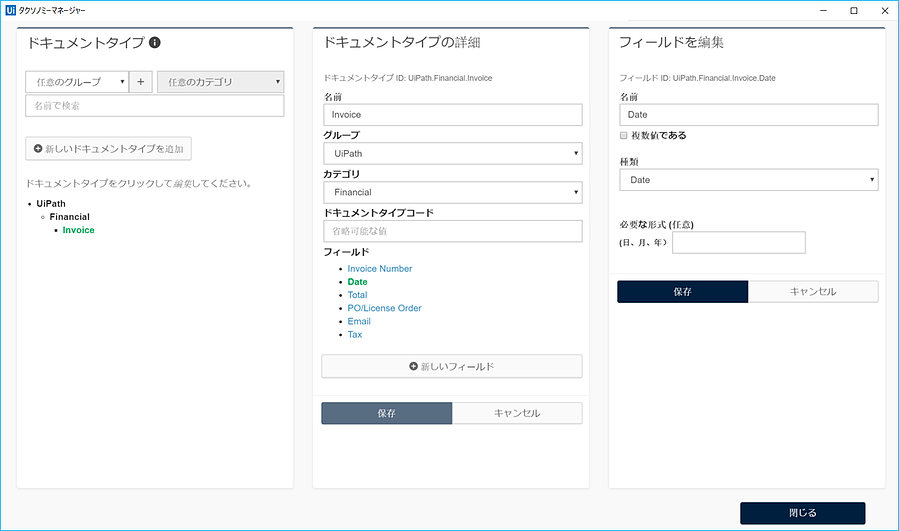
1.タクソノミーマネージャーからドキュメントタイプ及びフィールドを定義します。
Studio のデザインツールバーにある「タクソノミーマネージャー」をクリックして、タクソノミーマネージャーウィンドウを開けます。

タクソノミーマネージャーウィンドウからドキュメントタイプ(複数定義可能)及び各フィールドの詳細を定義できます。
定義されたタクソノミーはJSONファイルで保存されます。
2.「ドキュメントをデジタル化」アクティビティに任意の OCR エンジンアクティビティと組み合わせて対象ファイルを OCR かけます。
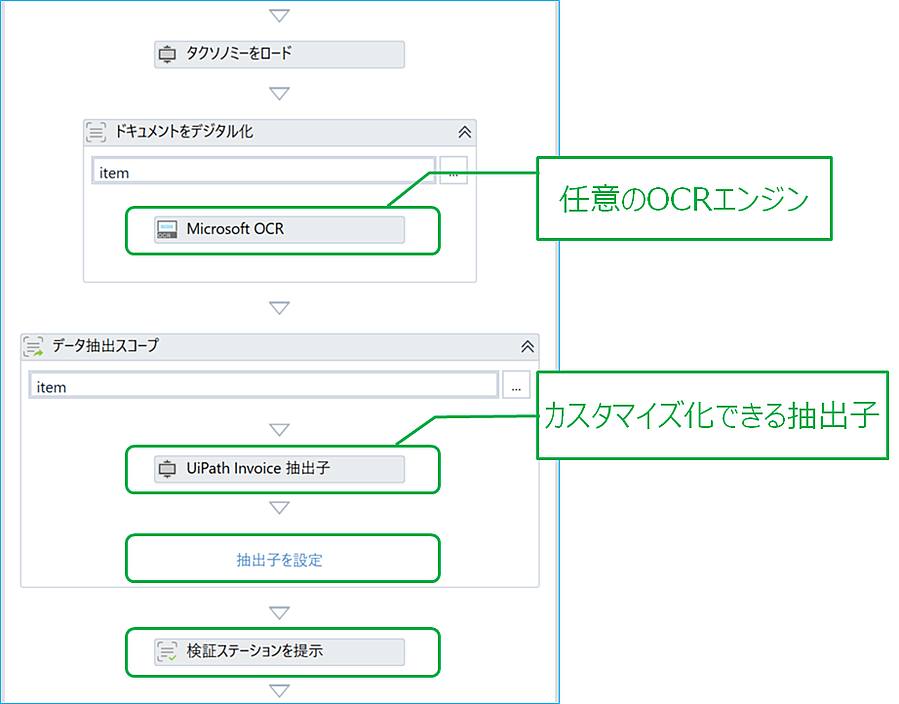
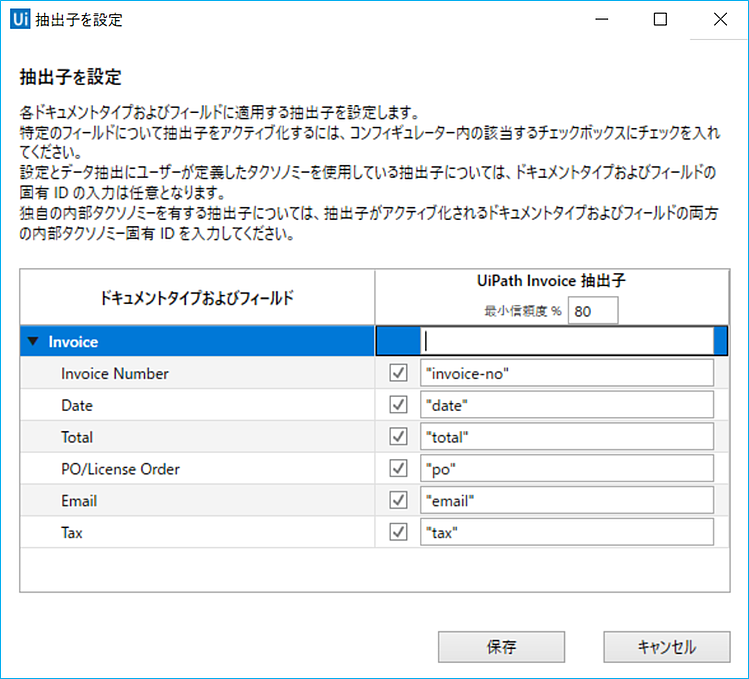
3.「データ抽出スコープ」アクティビティに抽出子を設定します。
現在、無償で使える抽出子は UiPath.MachineLearningExtractor パッケージがあります。

抽出子を設定ウィンドウから、各ドキュメントタイプ及びフィールドに適用する抽出子を設定できます。
4.「検証ステーションを提示」アクティビティを利用して、Attended プロセスとして UiPath 検証ステーションがロボット実行中に表示されます。
左側にある各 OCR 抽出されたフィールドのデータと右側にある元のファイルと比較して、自由に修正できます。
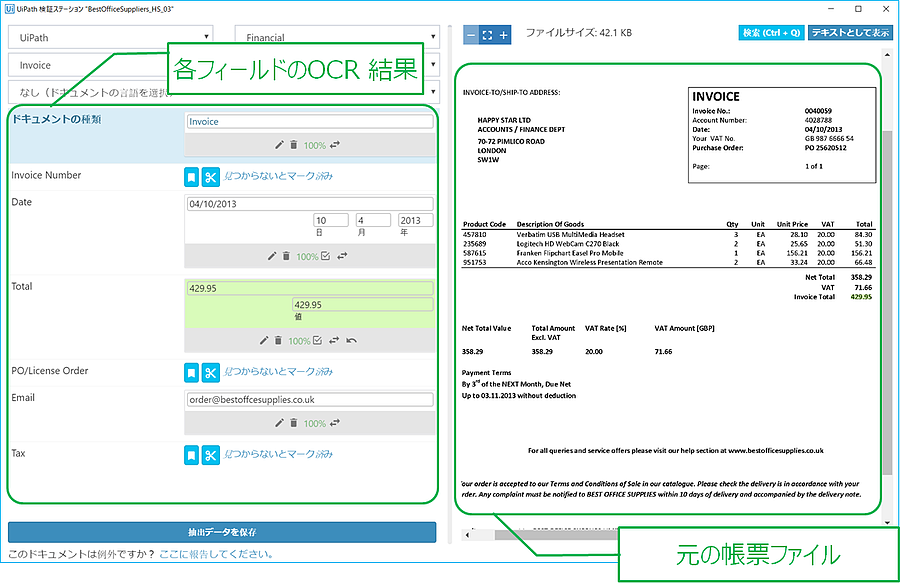
最後、「抽出データを保存」をクリックして、抽出されたデータをJSONファイルで保存されます。

ロボットがデータをさらに整形し、他のシステムに登録するなどの処理が考えられます。
おわりに
今回は、UiPath 組み込みの OCR アクティビティを利用する UiPath のドキュメント処理プラットフォームを説明しました。
今後の OCR によるドキュメント処理はより充実にできることを楽しみにしています。
Technical Program Manager, UiPath
Related articles


Get articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.
Get articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.