
How to Start a UiPath Document Understanding Project
Share at:

Introduction
Every organization uses different documents daily to perform business activities. Processing documents can be time-consuming if it requires manual effort. UiPath Document Understanding helps business units to process documents automatically, assuring high accuracy and reliability.
Every document understanding project comes with its own set of trials. Some of the main challenges in intelligent document processing are the variations in documents, the complex business rules, and the technology required to process the high volumes. It's essential to understand these elements, at the initial stage of the project to build a cost-effective, reliable, efficient, and scalable solution. Before getting started, you'll need a basic understanding of the UiPath Document Understanding Framework.
Building the scenario
The complexity of a document understanding project can range from a simple, straightforward process to a highly complex process with multiple document types in different languages. Identifying all the possible scenarios at the initial stage of the project helps RPA solution architects and developers plan the solution and think of the technology needed to process the documents. At a high level, a few factors require attention in any document understanding project.
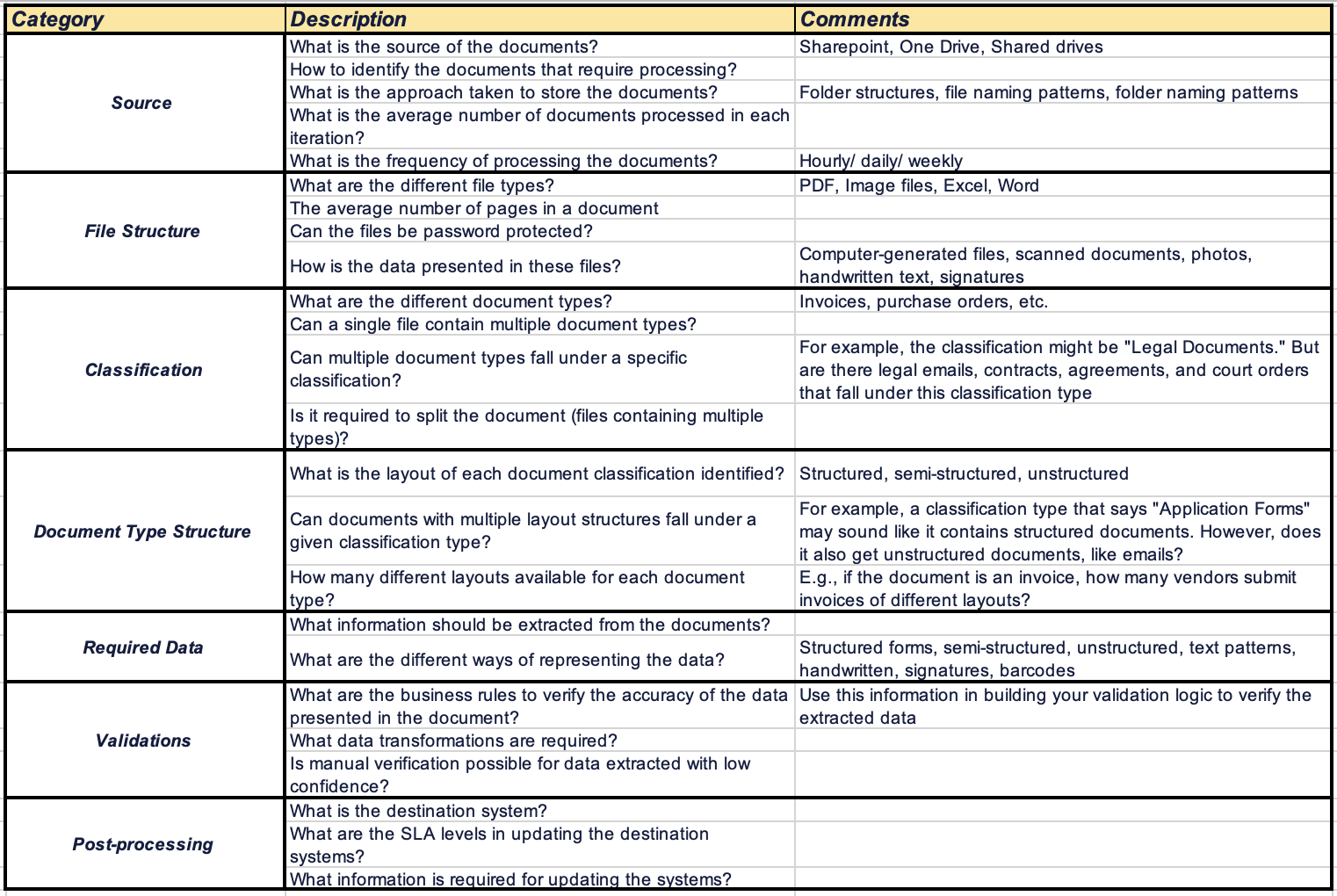
These can be considered a checklist to gather requirements for any document processing automation project.
Let's now look at how we can use this checklist to gather information and plan the way forward.
Step 1: Requirement gathering
Like any other RPA project, understanding the clear requirements is vital for intelligent document processing projects. Using the checklist provided above gives all the insight we need about the documents involved in the process. Talk to business users and understand how they process each document type, the information extracted, and how they validate it before updating downstream applications. Other than capturing the business requirements, requesting sample documents of each identified document type is also important. Request for all possible variants to uncover the points mentioned in the "File Type Structure," "Classification," and "Data Extraction" sections in the checklist. Additionally, going through the files most of the time uncovers hidden scenarios that require addressing during development.
Step 2: Planning the solution
Compare the samples received with the business rules described to identify the techniques required to process the document. The checklist provides excellent insight into some of the techniques needed. Document processing automation typically needs to have three main modules. A module where the documents are collected, where they are orchestrated, and a post-processing model.

As a best practice, the three-module architecture should remain the same across all Document Understanding projects. The architecture of each module may depend on the information identified through the checklist mentioned above. The data handover between the modules requires a data store such as the Orchestrator Queue. Using Queues for the data transition has more benefits than other approaches because of the built-in retry capabilities and the ability to run multiple jobs on the same queue without duplication.
Step 2.1: Document collection module The section "Source" in the checklist provides all the information on how the files are stored, access methods, and the required logic to identify new files. It's crucial to plan the architecture based on the information gathered from this section. The checklist provides information on how to identify new documents. However, we need to have a mechanism to ensure we don't process the same document multiple times in case the process runs into an unexpected error and needs restarting. The source system may provide us with information to identify new documents. Hence, it's essential to use a secondary data store to maintain a record of items. The monitoring can be done through Orchestrator Queues, Data Service, Excel, or a SQL database.
Step 2.2: Document understanding module There are several sub-sections that require configuration during development.
1. Defining the document types and the data fields required for each type
2. Digitization of the documents
3. Classification and document splitting strategy
4. Data extraction strategy
5. Model retraining strategy (if applicable)
The requirement for these subsections must be clear before proceeding on any Document Understanding project. Defining document types and data fields Defining the document types and the fields depends on insights gathered through the "File Structure," "Classification," "Document Type Structure," and "Extract Data" categories. It's essential to define the document types at the most granular level according to business requirements and group them accordingly. One of the other important points is the types of documents that fall into one specified category.
For example, in invoice processing, the type "Invoice" contains invoices. However, we come across scenarios where each defined type may contain multiple types of documents. For example, "Requisition for Release of Information" may contain court orders, court reports, email communications, requisition forms, and many more. Identifying these scenarios is essential when defining the document types and planning the classification.
Digitizing documents and use of OCR engines Document digitization requires an OCR engine to convert scanned documents or images to a machine-readable format. The selection of the OCR engine depends on how accurately it extracts data from the documents. One OCR may work well on one project, but it may not work well on other types of documents. Hence, identify OCR engines that support all identified document variations (computer-generated, handwritten text, scanned documents, and photos). Next, perform an OCR benchmarking test to compare multiple OCR engines on actual samples to identify which OCR engine performs the best.
The advantage of benchmarking tests is that it also helps identify which scenarios and data fields require more focus in validating the extracted data. Classification and requirement for pre-trained classification models
1. Using the classification model depends on the documents - following is a simple guide to performing the selection
2. Use Keyword Based Classifier if the documents are straightforward and if you can easily define the unique keywords
3. Use Intelligent Keyword Classifier if the file contains multiple document types that require splitting
4. Use Machine Learning Classifier if the documents are mainly unstructured and have many variations making it challenging to specify unique keywords
However, depending on the use case, you may also find scenarios that require performing splitting on largely unstructured documents with many variations. In such cases, approach the classification in a way where you use multiple classifiers to support all the requirements. Identify the primary classifier based on the required functionality and accuracy, and use other classifiers to support the primary classifier to generate the expected outcome.
Data extraction and selection of extraction models The selection of the extraction method depends on several factors described in the "Data Extraction" section of the checklist. The extraction method mainly depends on the methods used to represent data and the document layout. Use the following questions as a guide to decide which extractors to use.
What is the layout of the document?
1. Structured and has a fixed number of rows in tables? Forms AI, RegEx Based Extractor
2. Structured, but doesn't have a fixed number of rows in tables? Check out Form Extractor (multiple templates), Forms AI
3. Semi-structured and many layouts? Loot at ML Extractor (custom or out-of-the-box)
4. Unstructured – language analysis models based on the values to be extracted (NER, Semantic Analysis, Classification)
5. Is it required to check the availability of signatures and checkboxes? Use Form Extractor
6. Is it required to identify a signature and extract it for comparisons? Object detection models or Form Extractor (crop and extract using signature area coordinates)
7. Can we use multiple extractors? If you see a combination of all of the above, we can use multiple extractors as required. We can use multiple extractors in scenarios where one extractor isn't performing well on certain documents or patterns. The secondary extractor can help on such occasions.
Model training and retraining Training a model for classification (Keyword, Intelligent Keyword, or ML Classifier) is performed based on the documents and the task we need to achieve. Consider the following when performing the initial training of the classifiers. For large documents (a file that belongs to one type but has several pages) - use Keyword Classifier and manually define the unique keywords.
For large documents (a file that contains multiple document types and has several pages that belong to each type) - split the file into multiple documents that contain a single page.
Use those single-page documents to train the classifier for each type. (This way, the classifier learns to understand each page individually and predict accurately).
UiPath also provides an extensive collection of out-of-the-box ML models for data extraction. It's essential to evaluate whether the available models can serve the requirement when there's a need for Machine Learning Extractors. If the pre-trained model doesn't meet your requirements, consider the following when performing the initial training.
Collect a good number of documents for each document type you wish to train. The higher the number of samples, the better the model can predict.
It's recommended10–50 documents for each layout for training documents with different layouts (e.g., invoices).
Conclusion
Large amounts of data in organizations are stored in documents for various reasons. Document processing projects may contain complex documents and business logic that require configuration. However, following a checklist to capture all those scenarios helps ease the development activities for document understanding projects. Furthermore, having the correct information helps you plan the solution to use. Having the perspective on the required technology and techniques is essential to ensure the delivery of a scalable and reliable solution.

Country Director, Boundaryless Group
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.