
Better Business Outcomes by Operationalizing Artificial Intelligence at Scale
Better Business Outcomes by Operationalizing Artificial Intelligence at Scale
Share at:

Artificial intelligence (AI) is powering a new normal for businesses across industries. Retailers can, for example, use AI to predict purchase orders on historical inventory data to drive intelligent restocking decisions. Customer support teams can use AI to automatically respond to and route high-priority customer support tickets to the right teams. There’s a world of possibilities where you can use AI, and specifically ML, to drive practical business outcomes.
According to Deloitte Insights, 83% of enterprise AI early adopters saw a positive return on investment (ROI) from projects in production. These included examples such as the implementation of third-party enterprise software using AI, use of chatbots and virtual assistants, and recommendation engines for e-commerce platforms. Eighty-three percent of companies surveyed planned to increase spending on AI in 2019. Of the enterprises investing in AI, 63% had adopted ML.
Building a strategy for pragmatically using AI and ML to achieve business goals is a top priority for many enterprises. For many, the main challenge to successfully operationalize ML is understanding, planning, and executing management of a holistic ML deployment across the organization.
Top considerations for operationalizing ML
The ‘right’ way to tackle the data science lifecycle differs from one organization to another. Many attempts have been made to codify and standardize data science lifecycle procedures. However, no one approach incorporates the needs of every enterprise.
Embracing a sustainable and maintainable strategy for data and data science is an ever-evolving exercise distinct to each enterprise. Because every company’s needs, structure, and capabilities are unique, stakeholders from across the enterprise must be consulted to build a flexible and scalable ML model and execute a holistic data science strategy.
The operational challenges and changes to infrastructure and development practices each enterprise must address will differ.
It is critical that your organization take into consideration your culture, systems, and needs while defining and evolving the data science lifecycle. Having a base framework to present across teams helps develop a common basis for communication while you continue to develop and evolve your operationalization of ML.
Let’s walk through a standard framework that can help your organization get started on its ML journey.
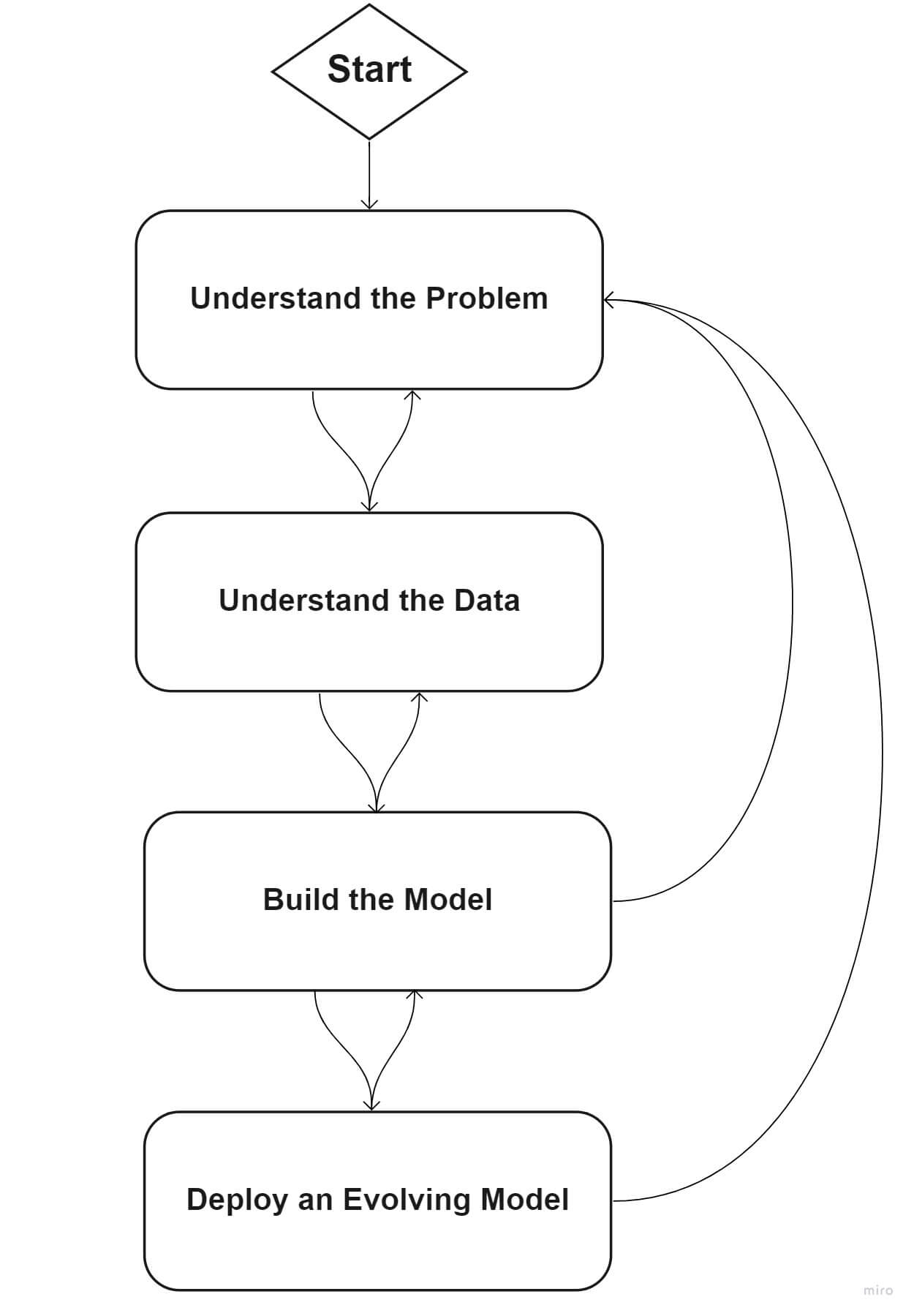
Phase one: Define your problem
At the core of any ML initiative are two questions:
1. What problem are you trying to solve?
2. Why do you believe ML and a better understanding of your data can help you solve the problem at hand?
The answers to these questions depend on how your company thinks about strategy and evaluates business problems.
During phase one, key stakeholders should come together to define the initial scope of the problem and its requirements.
Phase two: Understand your data
What’s your data’s story? Where does your data come from, and how many data sources are relevant to helping you solve your specific business problem?
During this phase, enterprises focus on:
Mapping out relevant data sources and the environments they live in (such environments may be on-premises or in the cloud, set up as a data warehouse, data lake, or streaming data platforms)
Defining which data pipelines currently exist, and which data pipelines need to be built for data validation, cleanup, and exploration
Understanding how frequently data is updated
Understanding the trustworthiness of the data
Evaluating data privacy considerations and requirements
Enabling data exploration through visualizations, statistical properties of raw and transformed data, etc.
Understanding your data is no small task. It’s important to approach this phase iteratively. As you discover more about your data, you may discover issues impacting your ability to solve the problem which may further require that you redefine or rescope the problem from phase one.
Phase three: Build the ML model
Once you have the data ready, it’s time for your data scientists to build an ML model. Common steps to build a robust ML model include:
Extracting and engineering features (includes binning, data whitening, and applying statistical transforms)
Selecting features
Training the model (includes splitting the data into any number of training, cross-validation, and validation data sets)
Tuning hyperparameters
Evaluating the model
Validating statistical significance
Developing a model requires ongoing feedback from business stakeholders. For example, the business problem may call for an affinity to sensitivity vis-à-vis specificity. You may similarly tradeoff slight predictive performance (e.g., F1 score) for model operational performance (e.g., faster predictions), or model explainability.
The goal of the data scientist is to build a model that uses data to tell a clear story related to the business problem. As the problem evolves and requirements change, the approach to modeling must also evolve to serve the current context.
Phase four: Deploy an evolving model
Building the initial model is just the beginning of the ML journey. Deploying an evolving model is a crucial step to long-term value creation for the organization.
Deploying an evolving model requires:
Serving the model (making the model highly available and horizontally scalable)
Managing model versions (including rollbacks and canary/challenger deployments)
Retraining the model (modifying or building a new model as new data comes into the system)
Monitoring the model (tracking both operational and user experience metrics at serving and training times)
Monitoring data and model drift, requiring specialization of a model for targeted intra-organization use cases, and maintaining data pipelines (among other upkeep items) are critical for a model’s ongoing success.
Enterprise-wide and industry-wide requirements can evolve rapidly and impact data sources and inputs. For example, governance and compliance at scale are considerations spanning the full data science lifecycle.
Compliance with regulations—such as the European Union (EU) General Data Protection Regulation (GDPR)—requires a deeper level of traceability at the data versioning, model versioning, and model input layers. Building a strategy to respond to these industry changes and requirements through data can help companies continue leveraging ML to drive better business outcomes such as revenue growth, cost reduction, and decreased risk.
What’s next?
Operationalizing ML in a flexible, maintainable, and scalable manner requires many steps and considerations beyond the high-level scope of what we’ve outlined in this blog. The devil is in the details.
In our next blog, we’ll dive deeper into technical considerations, challenges that can arise from an ad-hoc implementation of a large-scale ML system, and how UiPath helps tackle common challenges for enterprise customers.

Senior Machine Learning Product Manager, UiPath
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.