
How to generate chronic disease prediction with UiPath AI Center™
Share at:

Introduction
Chronic diseases are a widespread challenge that affects healthcare systems worldwide. These conditions, generally long-term, include a diverse range of health issues. From cardiovascular diseases to certain types of cancers, chronic diseases contribute to a diminished quality of life. Costs, infrastructure, and resources in the healthcare system can be affected by the increasing numbers of chronic diseases.
How can we use technology in this sense? Artificial intelligence models can generate an impact, and the healthcare industry can be an early adopter. The following article talks about how we can effectively use lab data for early detection of chronic disease. This was one of the top ten use cases selected for the AI Challenge contest organized by UiPath Community.
Getting the dataset and training the model
UiPath AI Center™ allows you to deploy, manage, and continuously improve machine learning models. The most important aspect of the machine learning model is to have an exhaustive and varied dataset. The laboratories collect and process data for millions of people every day. So, they can be the source for having the diverse and representative dataset that is very important for building our data model. The quality of dataset determines the outcome of the ML model's accuracy. On the other hand, the ML model will first be trained on large sets of multivariate data from different laboratories.
The training dataset will include all types of patient data from different backgrounds and varied lifestyles. This will guarantee that our dataset is not skewed or biased towards any segment of data. It can also be used to do a cluster analysis (to determine if certain lifestyle factors or geographical locations impact the occurrence of certain diseases). The laboratory data will be confidential and will protect the individuals' identities. We are interested in the test results for different sets of people to build a comprehensive dataset.
Building the ML model
The first step in the process is to select the dataset. The data files from the different laboratories (stored in the form of .csv) will be collected and placed in a folder.
A good source of dataset is Kaggle. Just visit the Kaggle website and search for the health dataset to get a bunch of open data sets. You can choose the one that best fits your use case.
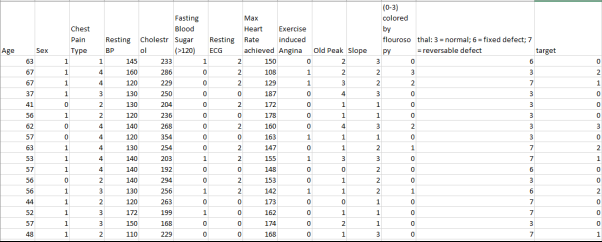
The entire folder can be selected as part of the dataset. For the dataset, we will assign numerical values for different conditions. For example: The following is one of the sample data sets. We will assign numerical values for different conditions (e. g, male and zero being female), chest pain type being either 1 to 4 as it follows:
Value 1: typical angina
Value 2: atypical angina
Value 3: non-anginal pain
Value 4: asymptomatic
The last column is the prediction result, with zero being no risk and 1 to 4 being the presence of risk in an individual.
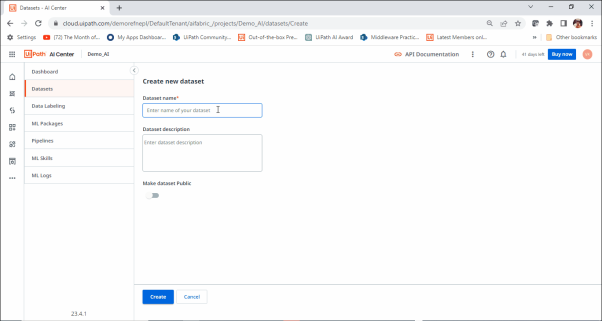
Once you have got the dataset file ready, it is easy to select the dataset as follows:
The next step is to select the correct ML model as shown below. As we have a multivariate dataset, we will go with the TPOTAutoMLClassification model. This will allow us to select the corresponding dataset with multiple parameters.

Now, select the pipeline and choose the package and dataset that was created earlier. We will first run the training pipeline for the model to be trained. Note: Follow the 80/20 rule for training and evaluating a pipeline. Make sure that you use 80% of your data for the training pipeline. The rest of 20% of the data can be typically used for the evaluation run.

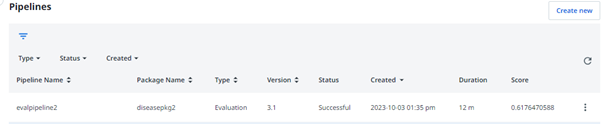
Once the pipelines have been completed successfully (the first run is expected to take more time, so you will need to be patient with it), the same process can be repeated with the evaluation pipeline run as shown below. The following image shows the evaluation pipeline execution for the same package. It is a similar process with the difference being the selection of a pipeline set and the corresponding input dataset.

In my case, the evaluation run was done and the percent score for the same was 61 percent.
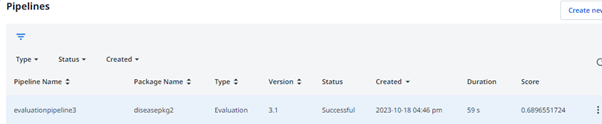
The percentage score depends on how well the data is distributed for the various sets of columns. I added more training data and then executed the evaluation pipeline again. The percentage score improved to 68.9 percent as follows.
Finally, the ML skills will be created, and the corresponding ML package will be selected for the run. To use this in the project, the developer just needs to include the UiPath.MLServices.Activities package. The developer then needs to pull the following activity and select the corresponding MLSkill package that has been created in the AI Center. For Example: The DiseaseMLSkill package in this example.
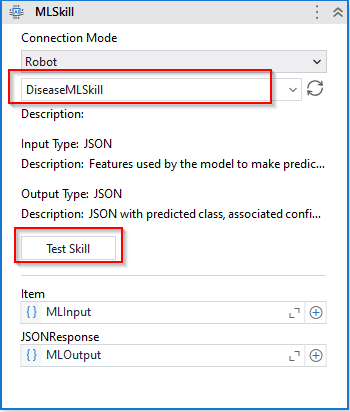
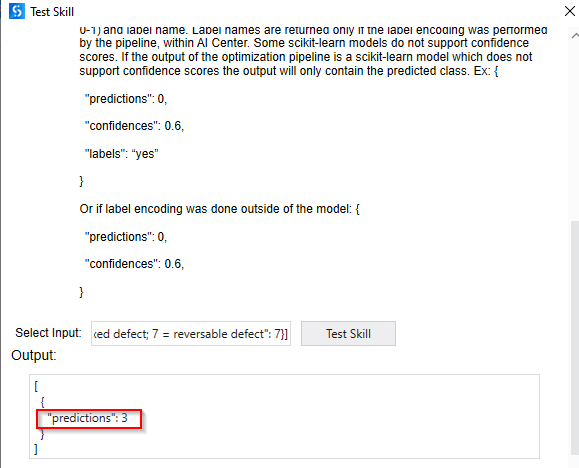
Another useful feature is the test skill option given for the ML Skill. This allows the developer to test the ML skill during development time itself. This expects the input in. Json format. For example: following is the example sample input that was used for testing the Disease prediction ML package. Note: The sample data needs to mirror the dataset and send the same attributes to get the target prediction.
[{"Age": 53, "Sex": 1,"Chest Pain Type": 4,"Resting BP": 123,"Cholestrol": 282,"Fasting Blood Sugar (>120)": 0, "Resting ECG": "0","Max Heart Rate achieved": 95,"Exercise induced Angina": 1,"Old Peak": 2,"Slope": 2,"number of major vessels (0-3) colored by flourosopy": 2,"thal: 3 = normal; 6 = fixed defect; 7 = reversable defect": 7}]
Once we have created this model, then we are ready to use it for our process flow. Let us go through it in detail now. Following is the to-be flow of what will be using the machine learning model to do the prediction.
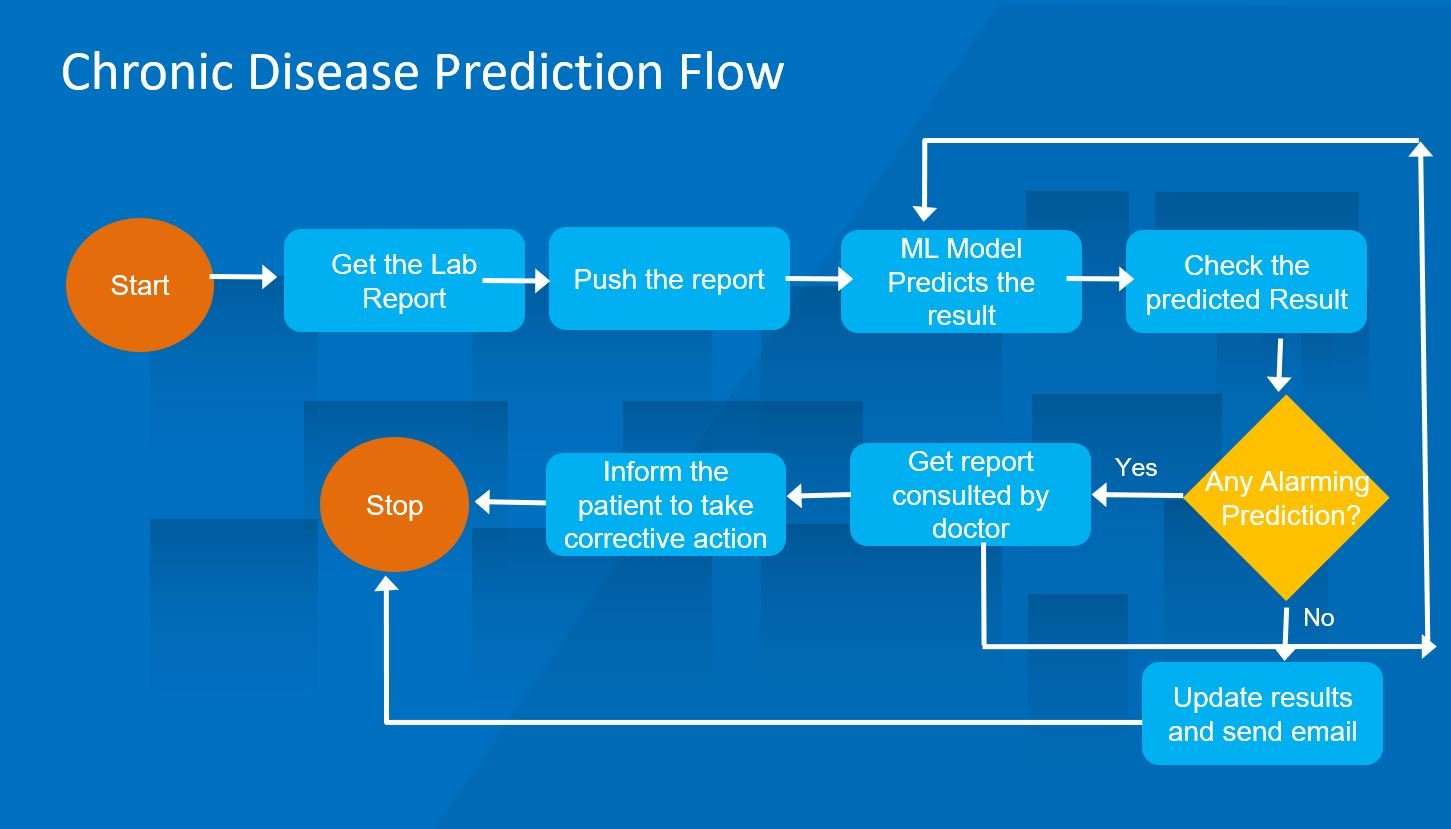
The flow for this new process will use the ML model that we created above.
The process will get the lab reports from email or other mechanisms.
These reports will be picked by the RPA process that will be triggered as soon as the email is received. Then push this report to the ML model for prediction.
The ML model will run this data and predict the outcome.
If there is an alarming prediction (where the target prediction is two or more), then the RPA process will send the report to a qualified doctor for verification. The doctor will validate the prediction (either via Action Center or on email) and once confirmed, the patient will be informed to take action.
If there is any change from what the machine has predicted, the new dataset will be pushed again to ML mode. This way better to improve the accuracy of the model going forward.
In case there is no alarming prediction, then the results will be updated and directly sent to the patient.
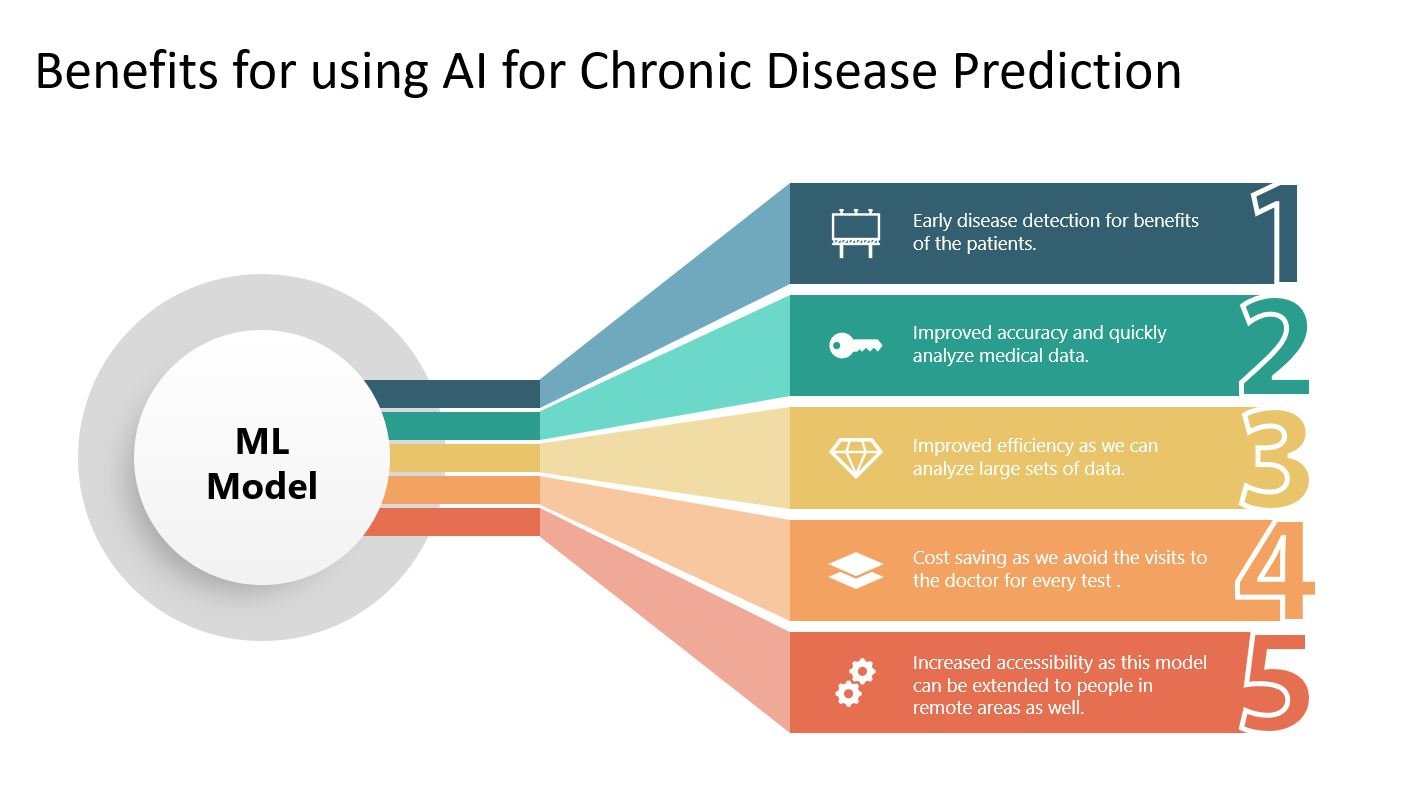
The model works fine with real data as well, and as we noted in the step above. For every change, we feed in the data again to increase the accuracy of the model. As we have the feedback loop from the doctor back into the ML model, the model will improve over time. We see benefits in the possibility of disease detection, improved accuracy, efficiency, accessibility, and cost savings.
Conclusion
Prevention, early detection, and effective management are essential when addressing chronic diseases. AI Center™ can provide a way to prospect the potential of AI in providing easier access to information, increasing efficiency, and improving outcomes.

Architect , Applications Software Technology LLC (AST)
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.