
How to use UiPath AI Center for Object Detection
Share at:

What is object detection?
Object detection is one of the primary tasks carried out by computer vision software to detect, localize, and classify objects in the real world. It involves the identification of a pre-specified object from either image or video data. Typically, object detection begins with a machine learning model assessing whether a specific object is present in an image or not. If the object is present, the software will create a bounding box around the object in the image. The model must then classify the object that is now outlined by labelling it as a specific object that was detected.
Once object detection is complete, the labeled image can then be used as a source of input in an automation workflow. Based on whether an object is present in an image, we could create an automation workflow to trigger an alert. This can be particularly useful for use cases in which a product should be in a specific place, such as on a supermarket shelf.
We could use object detection joint with an automation workflow to recognize when there is a gap on a supermarket shelf. Once we have detected a gap, we can set the automation workflow to send an alert to in-store staff in real-time so that they can replenish shelf stock. This is the example use case for the implementation below.

The problem with traditional computer vision-based object detection
One of the biggest issues with traditional computer vision is the amount of data that is required to train a machine learning model to function at an optimal level.
Neurolabs is using an innovative technology called synthetic computer vision. Instead of relying on real data, we use synthetic data, or digitally recreated copies or 3D models of real-world objects, to train and deploy our computer vision models.
So rather than having a human to manually, meticulously, and painstakingly collect, label, and process real data, we train a computer vision model to recognize real world products. This is currently the most popular process for mainstream computer vision providers and Neurolabs is championing the use of synthetic data. The aim is to achieve the same goals albeit faster, more cost effectively, and in a truly scalable way.

Synthetic dataset + ML model = next level of object detection
The Neurolabs platform allows you to rapidly train and deploy state of the art computer vision models using the power of synthetic data. Once you have access to the platform you can make use of any of the available digital 3D models or upload your own to use in your specific object detection use case.
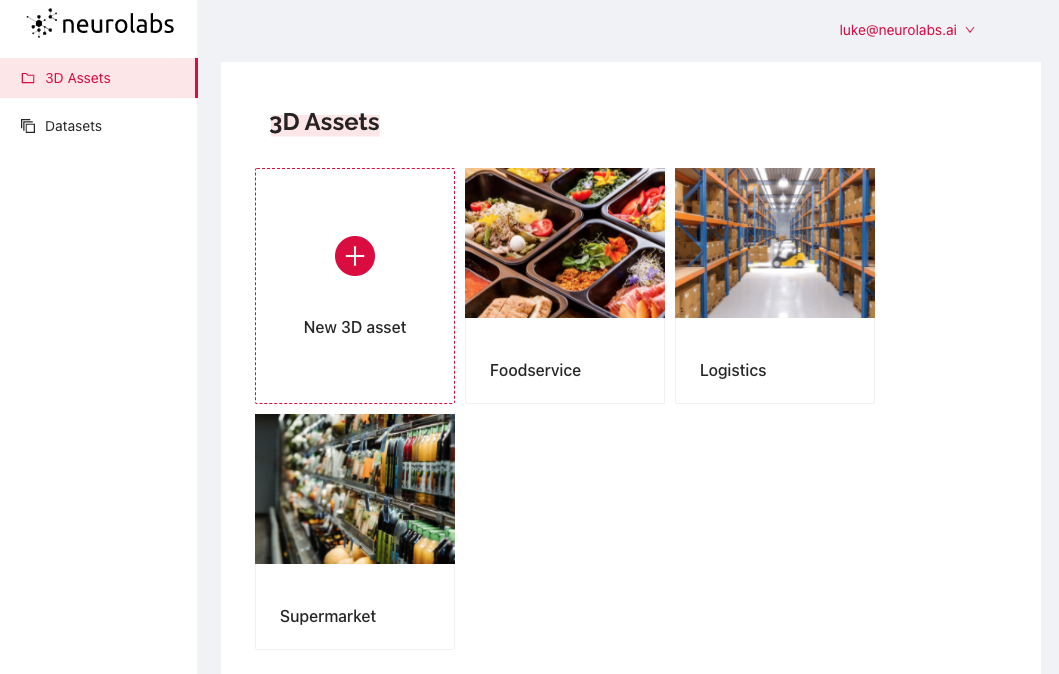
In this case, we are using an existing asset from our supermarket repository. The synthetic data here are digital 3D models of supermarket products, also known as Stock Keeping Units (SKUs). Rather than collecting thousands of images of the life SKUs, we have created digital versions to radically simplify the computer vision process.

Once we are happy that the object we need is available on the Neurolabs platform, in this case a digital twin of a box of cereal, we will create a synthetic dataset using its digital twin to train our computer vision model to detect it.
Simply click on "Datasets" in the left-hand side menu and then click "+ New Synthetic dataset". From here you can select the specific models that you wish to use in your dataset for model training. Here we have selected a variation of the cereal we want to detect.
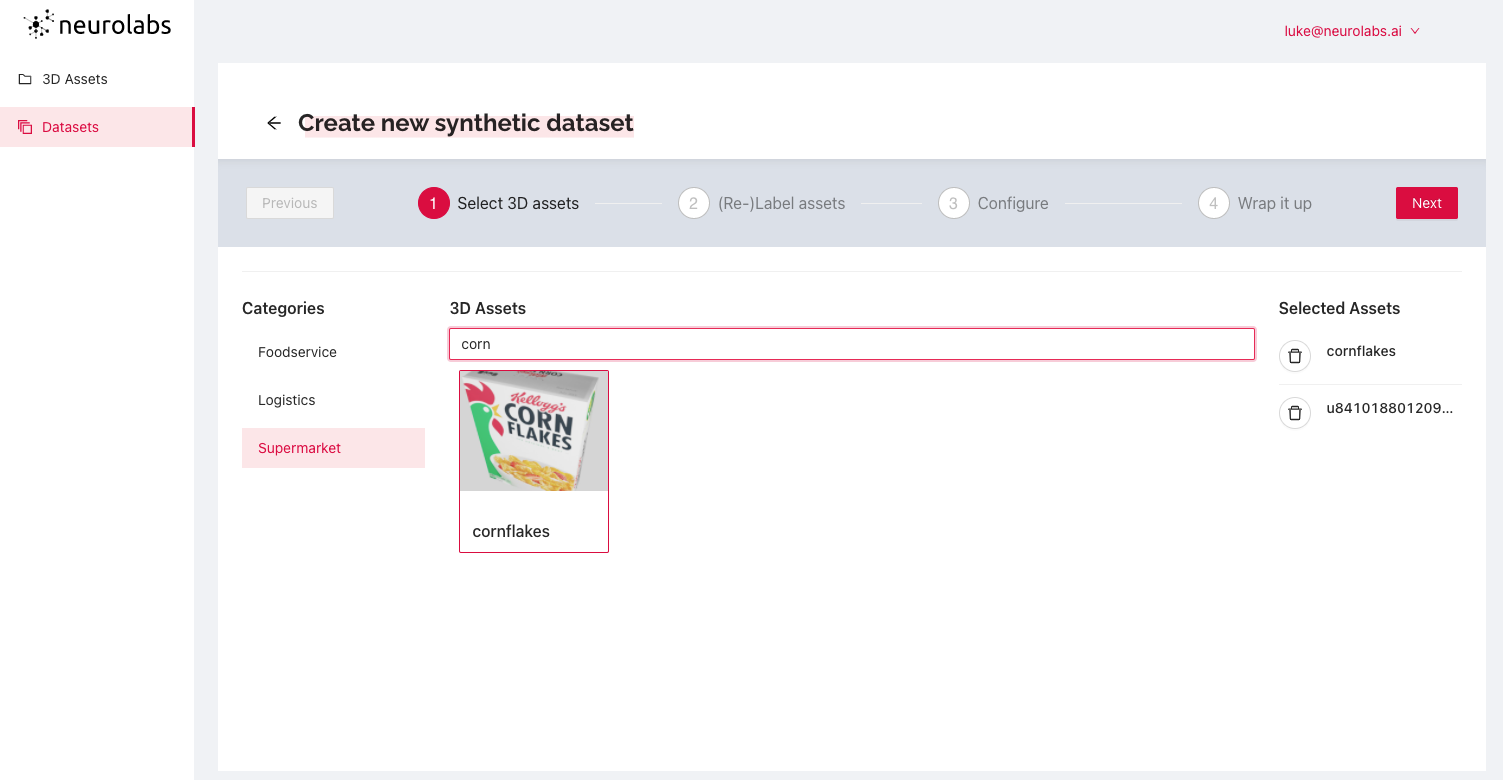
Next, the models are grouped by product type, in this case, cereals.
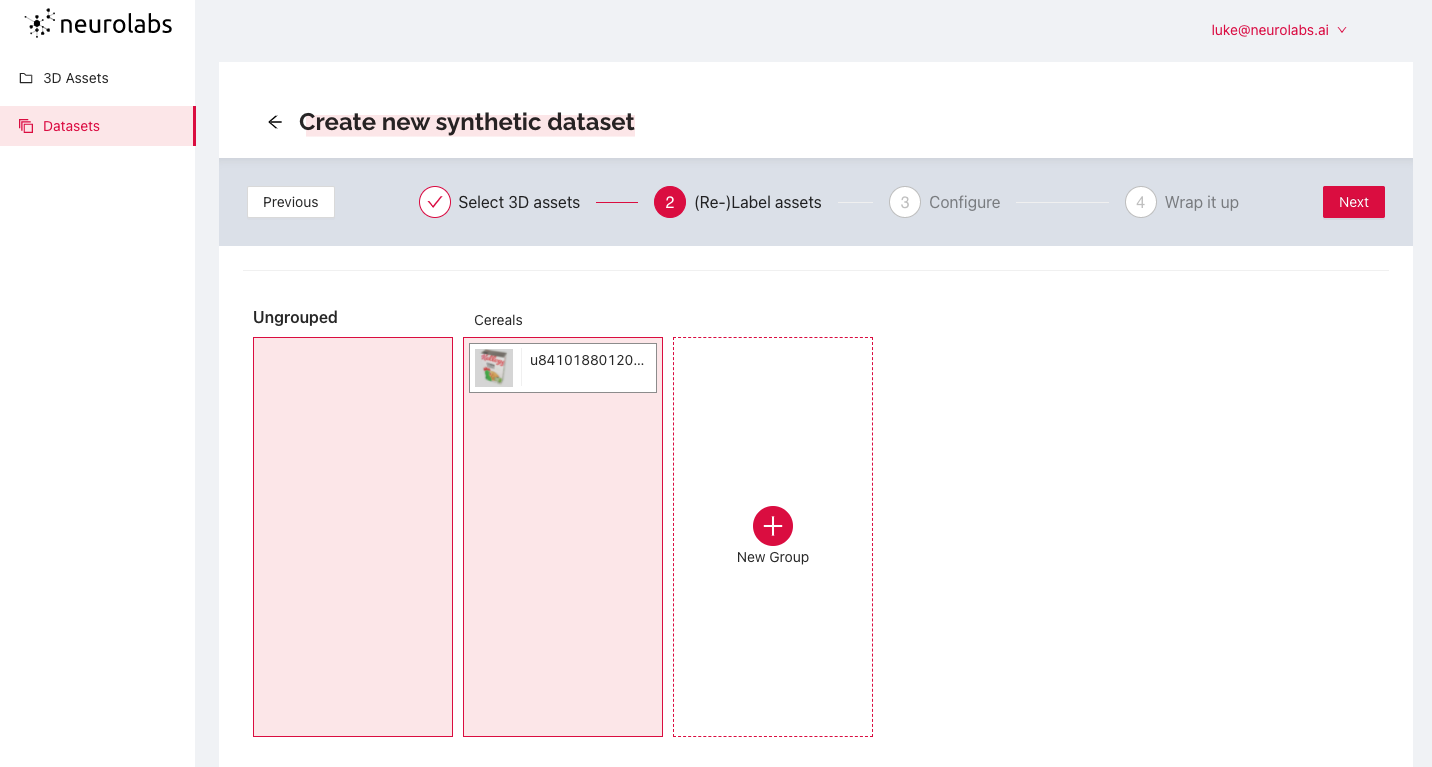
We can then configure a synthetic environment for the digital 3D models to be placed in for context and, as a result, improve detection rates. In this case, we have chosen several digital supermarket shelves as the setting.
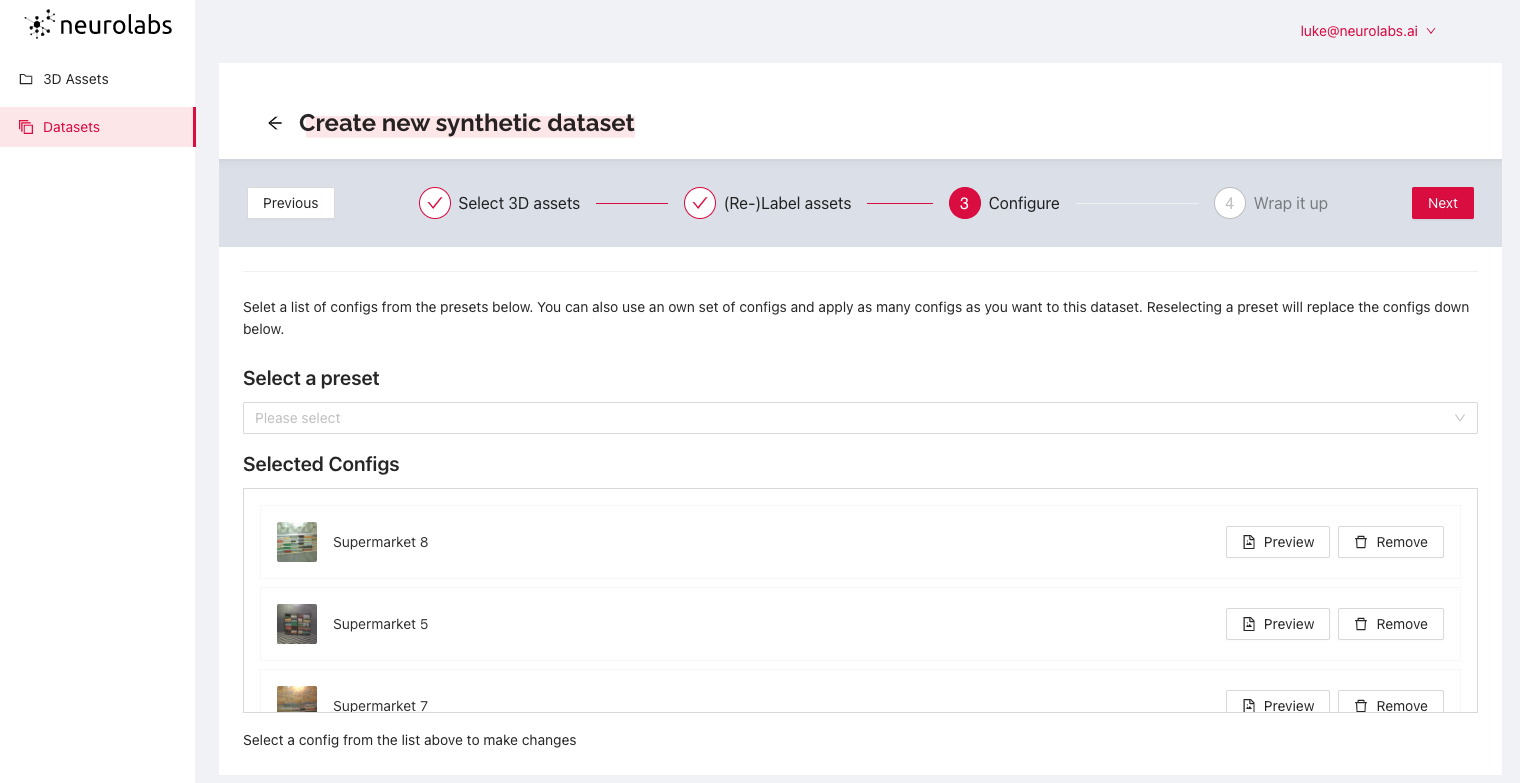
Once we are happy with the configuration, we simply name our new synthetic dataset and click "Finish".
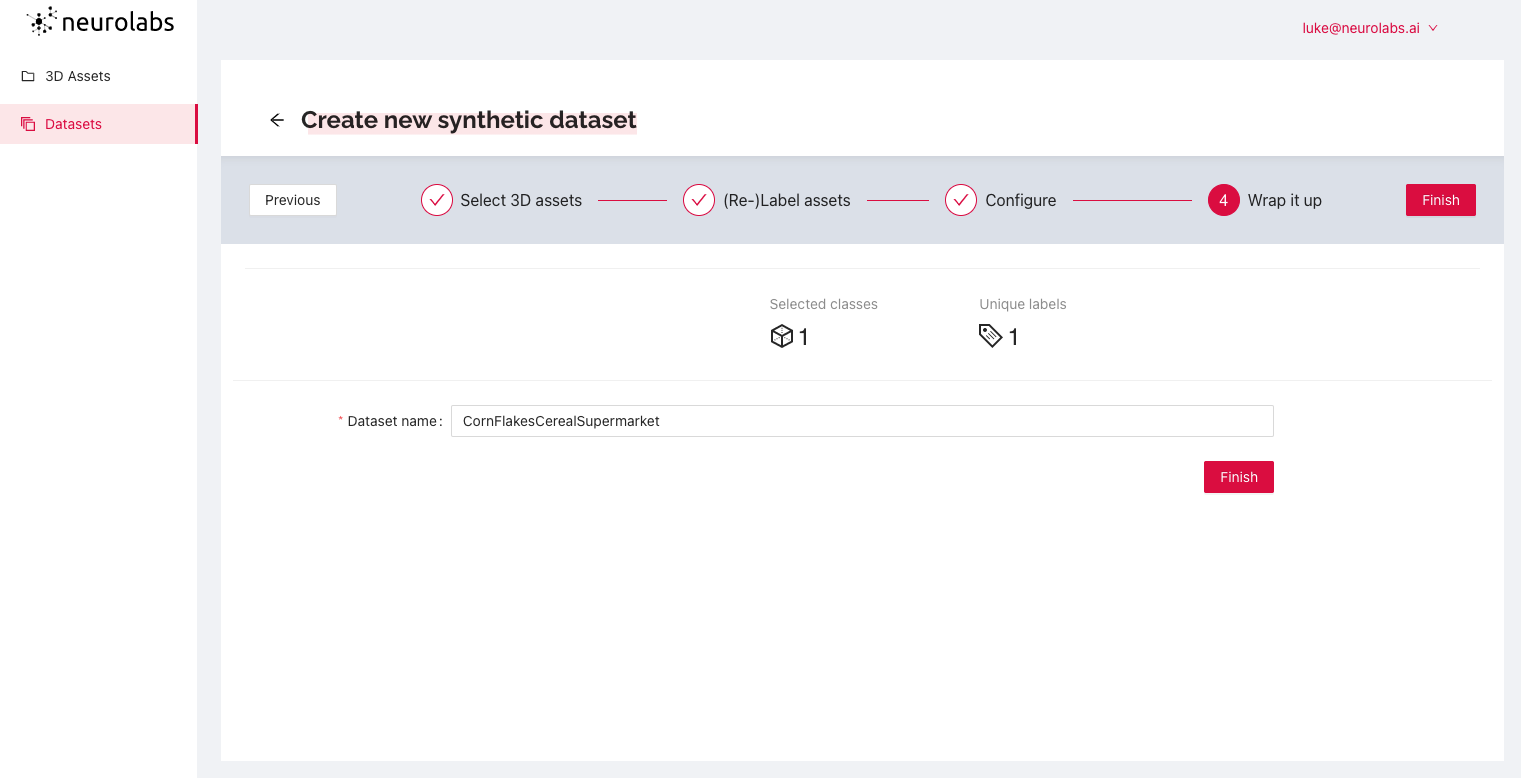
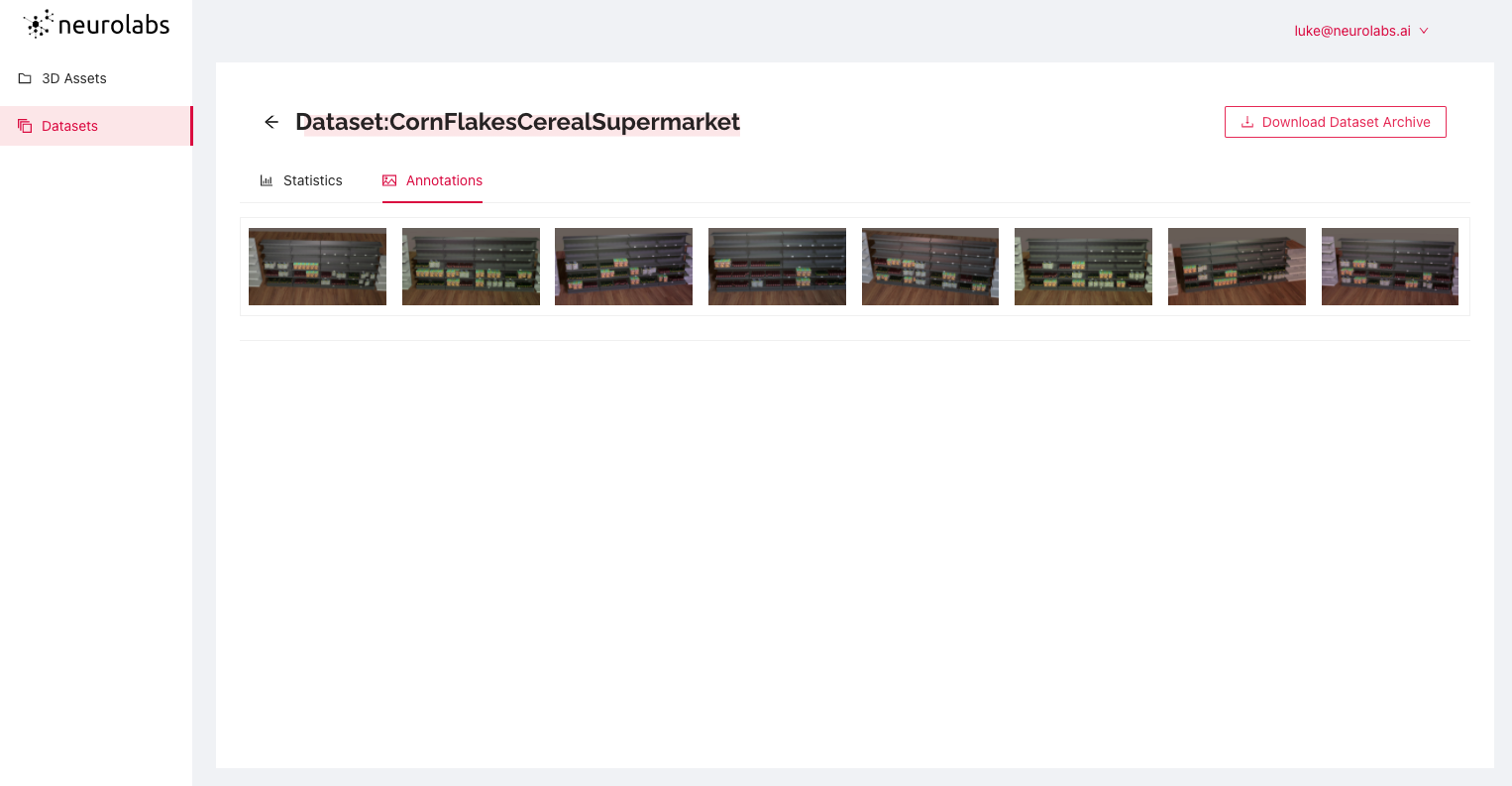
Your new synthetic dataset is now available to use from the "Datasets" of the Neurolabs platform. Simply click on the dataset to access its "Statistics" as well as view "Annotations" of your object in a virtual setting. You can download the dataset for model training by clicking "download dataset archive" This downloaded dataset can be used to easily train a computer vision model in UiPath AI Center.
How to use UiPath AI Center for object detection
UiPath AI Center is an easy-to-use service that allows you to deploy, manage, and continuously improve machine learning models. It also allows you to deploy them within RPA (robotic process automation) workflows via UiPath Studio. You can use the existing pre-built ML models, or you can build your own.
Below we will look at how you can use the UiPath AI Center to create an object detector starting from a preexisting ML Package and then re-training it is using our dataset from Neurolabs computer vision platform.
To get started you will need to sign up for the enterprise cloud trial with UiPath. You will then have access to the UiPath AI Center in Automation Cloud.
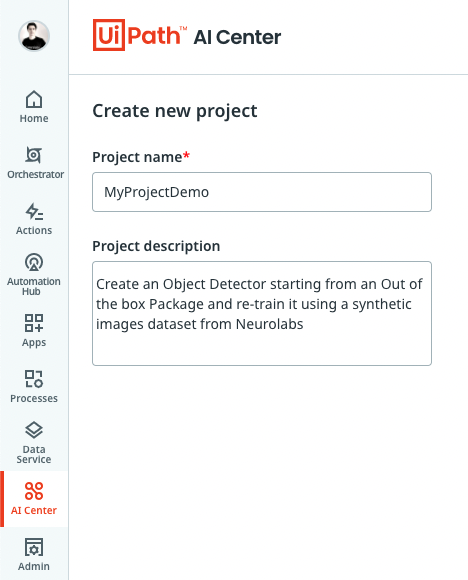
From the main page in the UiPath Automation Cloud, navigate to the UiPath AI Center and click on the "Create Project" button. Enter a project name and project description and your project will be successfully created.
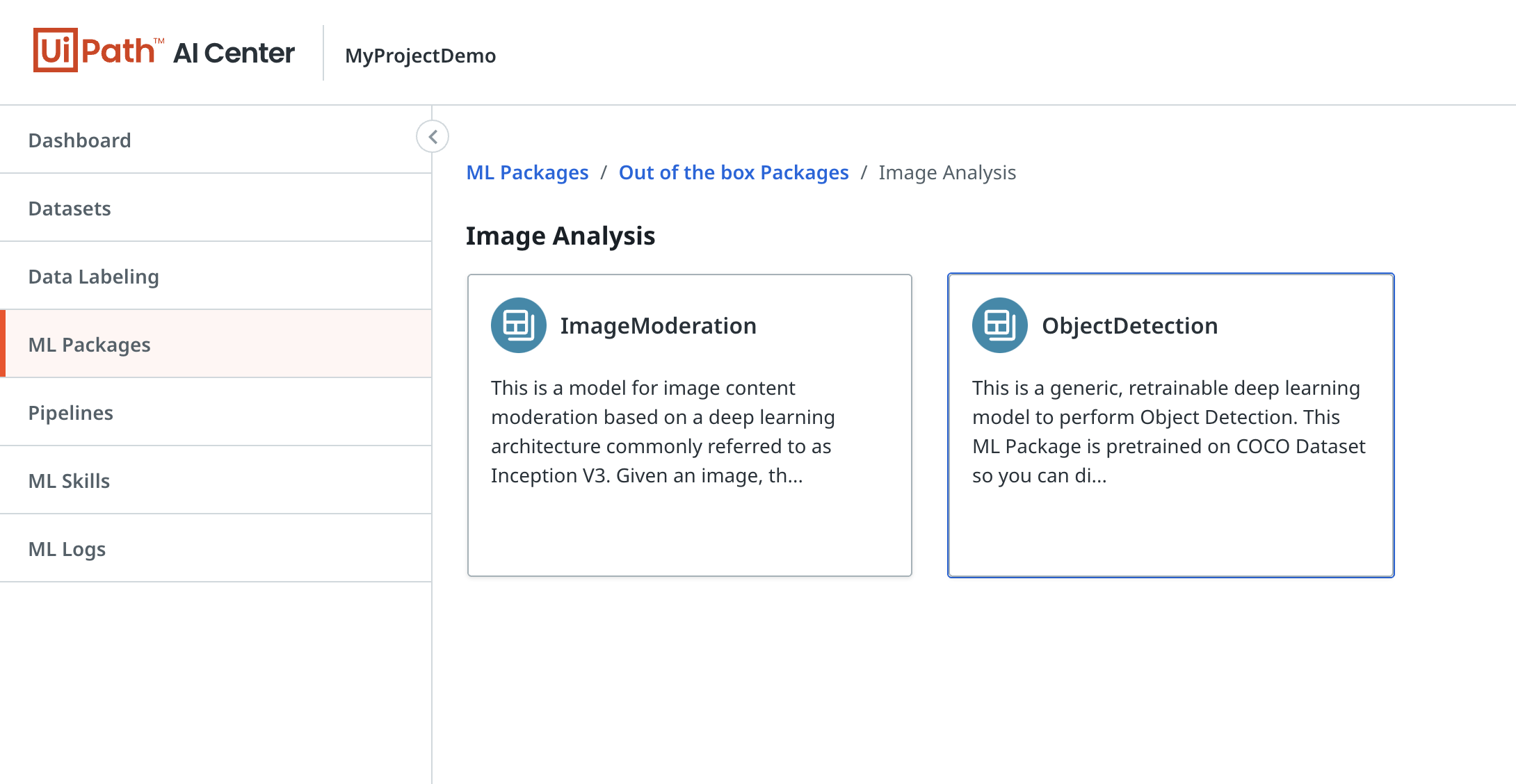
From the ML Packages section of the project page will create a new package by choosing an existing, out-of-the-box package, called "ObjectDetection". This is a generic, retrainable deep learning model that performs object detection. Once selected, it will be listed in the ML Packages table.
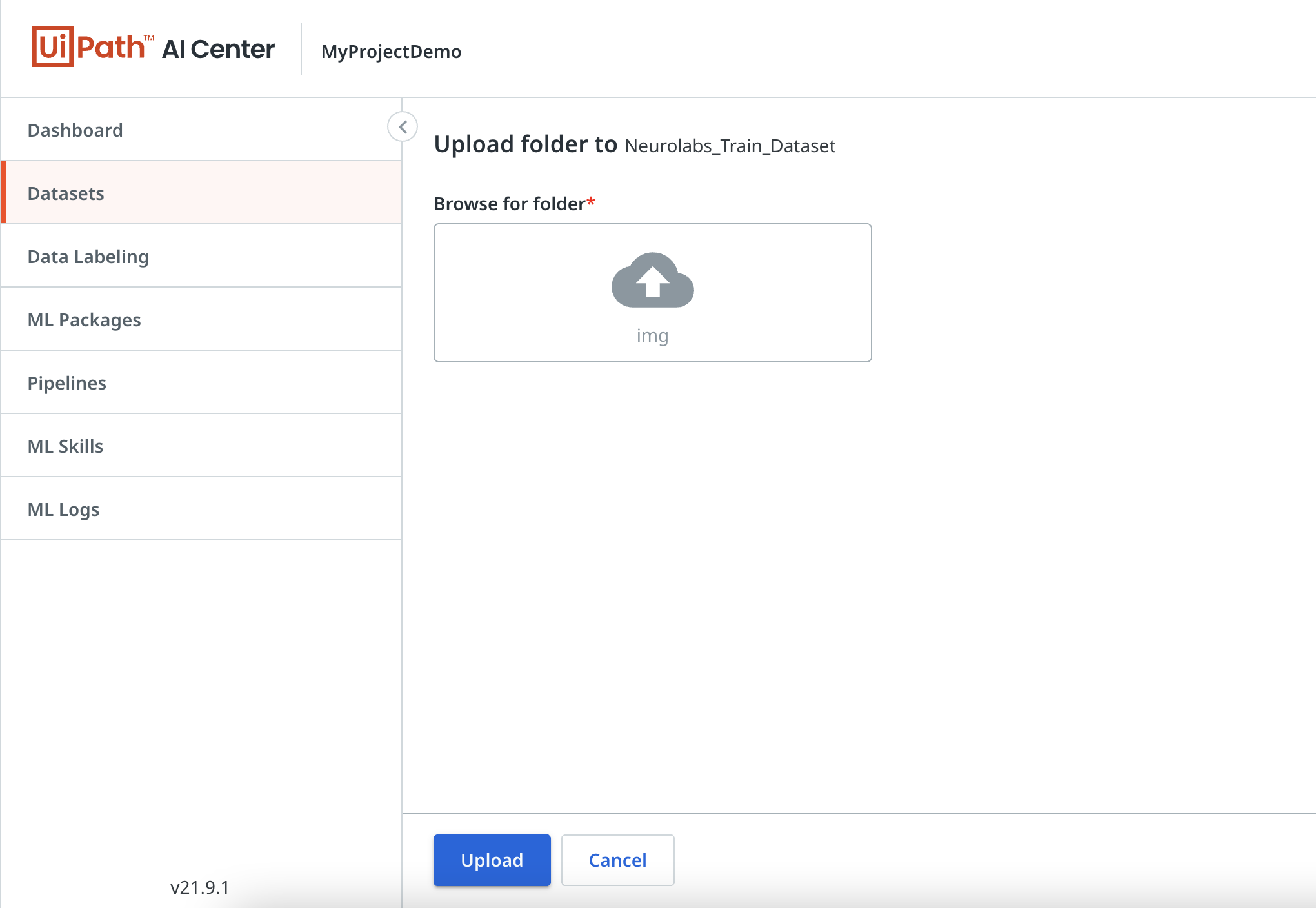
For this implementation, we will use the dataset of synthetically generated images from the Neurolabs' platform we created earlier. This includes both the images and the labels for the objects in scope, in this case, supermarket products.
To upload the dataset in our project, navigate to "Datasets" and select "Upload folder". Browse for the local folder and upload it.
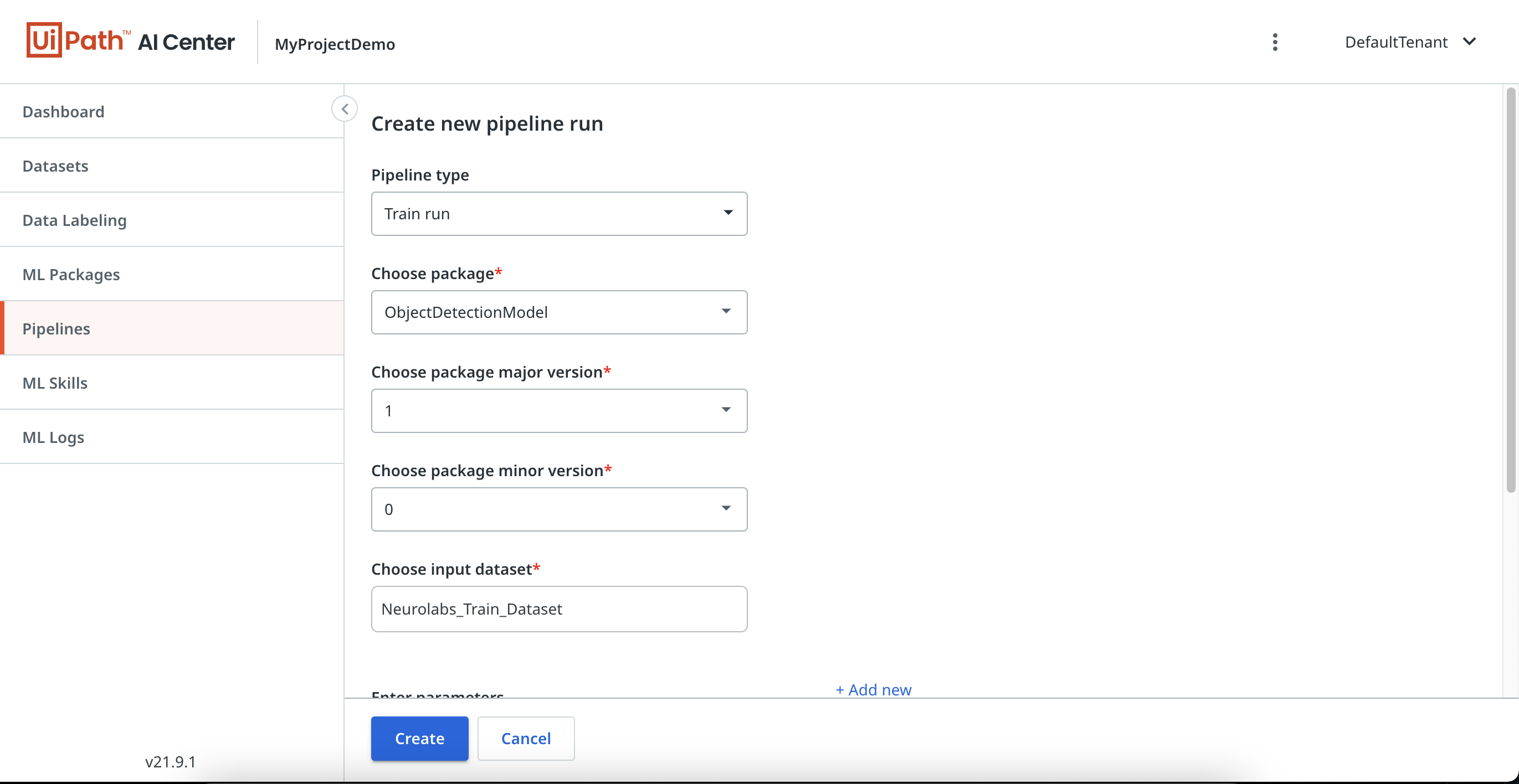
Once we have the ML Package and the dataset, we are ready to train the model and start using the uploaded data. To do this, we need to create a new pipeline. In the "Pipelines" section, select "Create new". Choose all the required parameters and the job is ready to start. The status can be checked in the Pipelines Table.
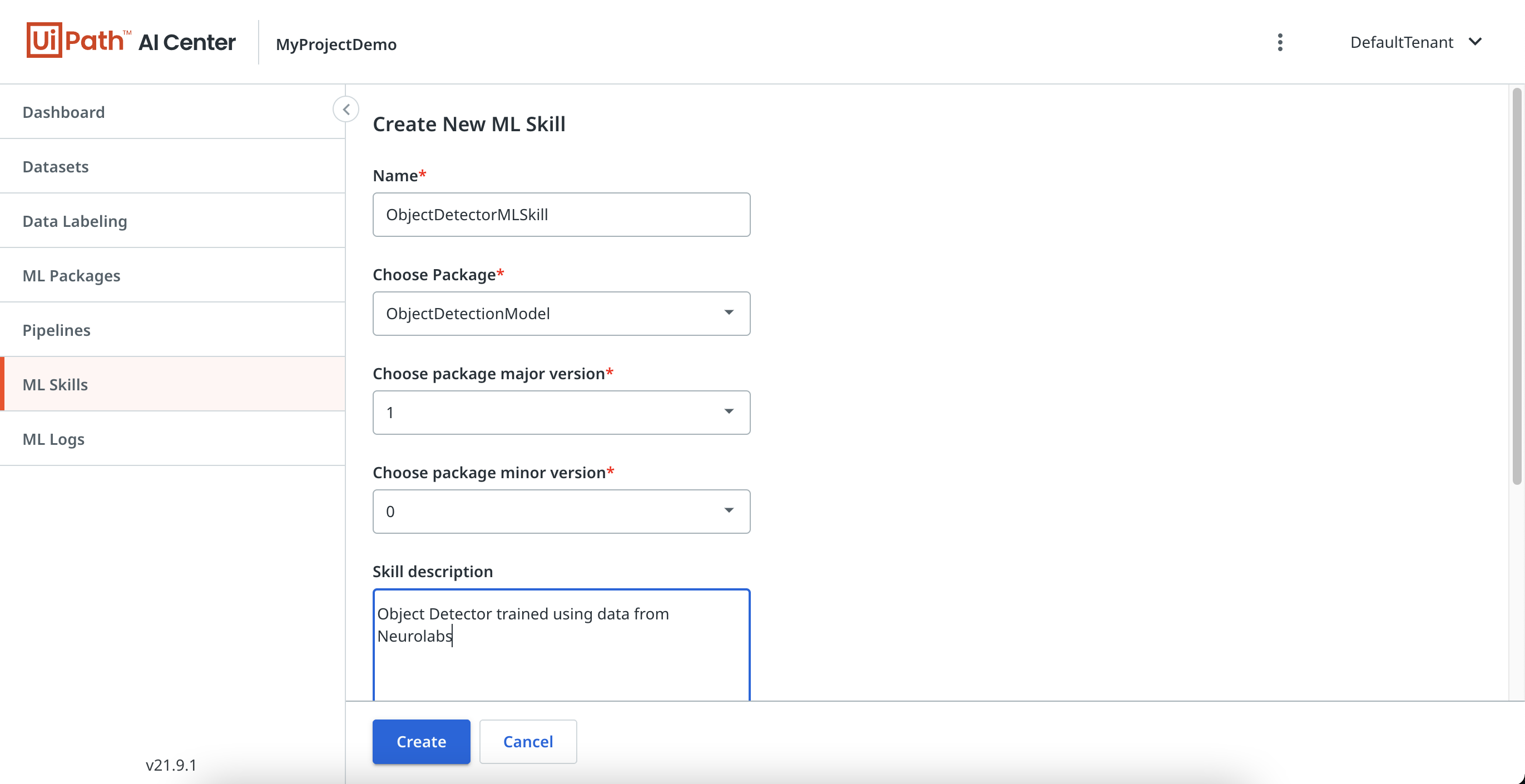
The last step to take in the UiPath Automation Cloud before we move on to the UiPath Studio is deployment. Go to the "ML Skills" section and select "Create New". Choose all the required parameters. Once the ML Skill is created, we are ready to use it in our automation workflows.
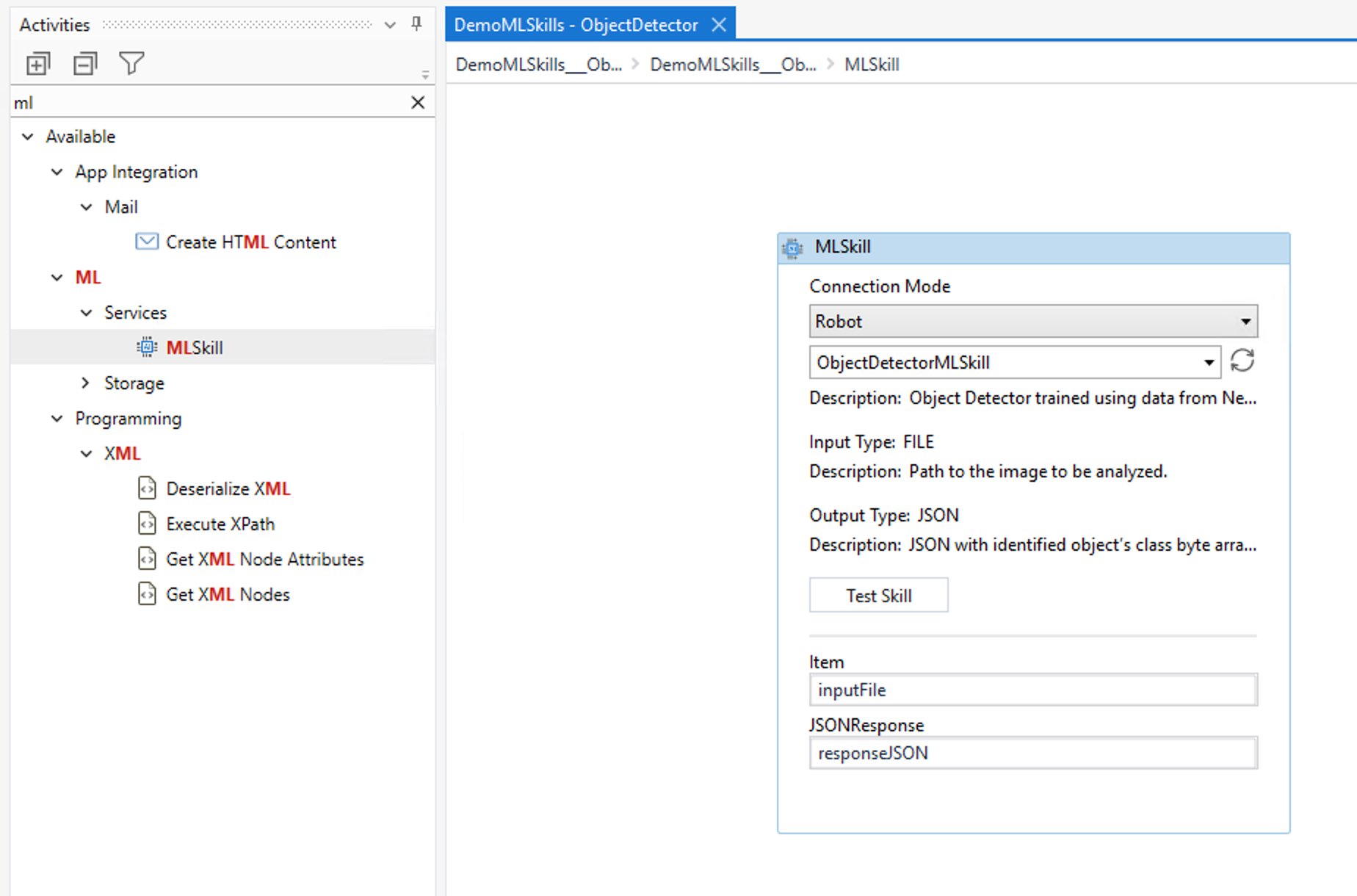
Use the intuitive interface in UiPath Studio to seamlessly insert ML models into your automations. We do this by using the MLSkill activity part of UiPath. You can easily test the ML model before you run it and scale them with as many robots as you want. By following this approach, we can combine the power of synthetic computer vision based object detection with automation to radically reduce the time and cost that would typically be incurred if a human were to manually carry out these processes.
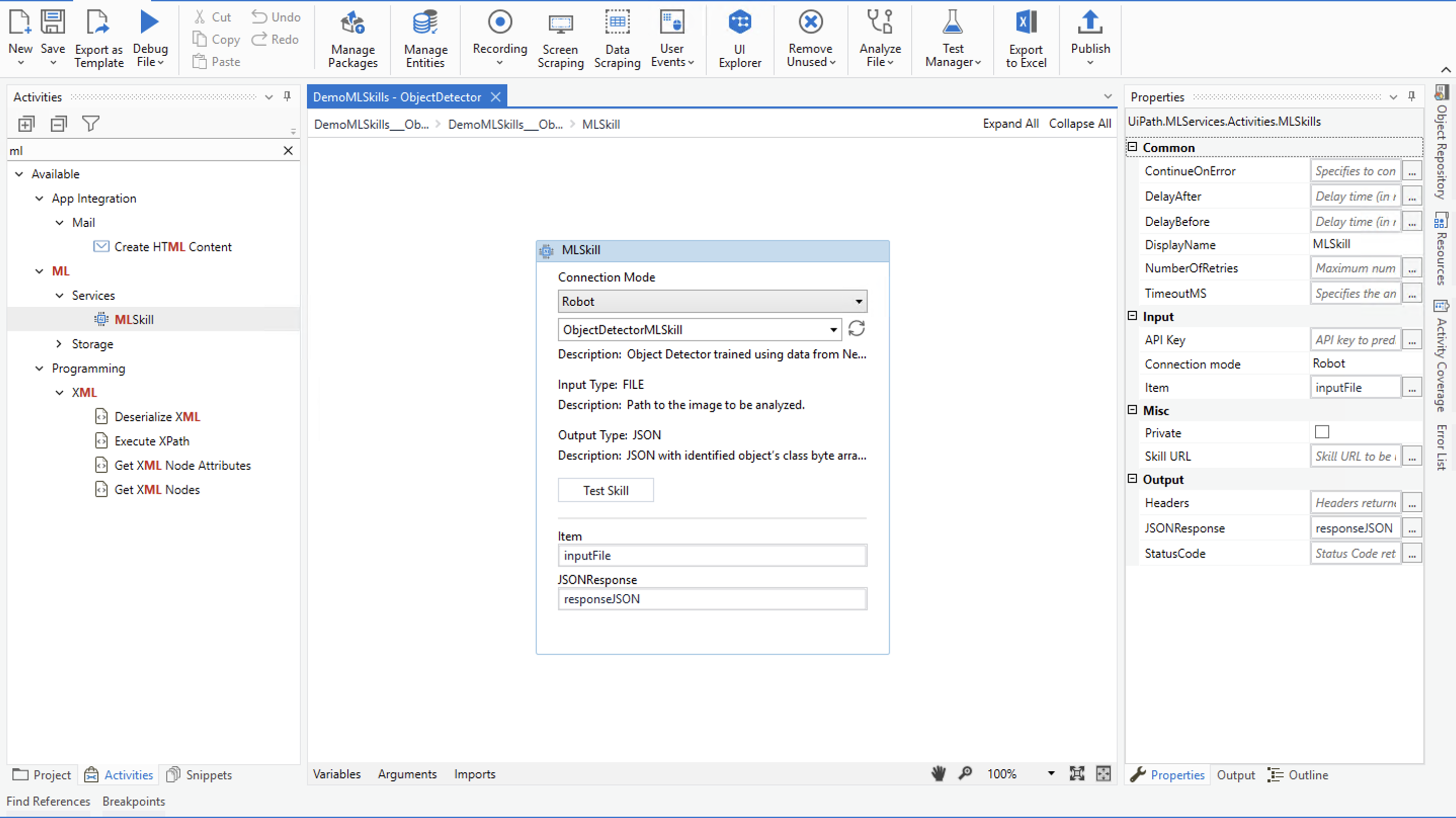
Once you have trained the UiPath ML Model with your Neurolabs synthetic dataset and set up your automation workflow in UiPath Studio, you should now be all set to deploy your new object detector in production. Your synthetic computer vision model will detect any object that it is trained to detect from any image that it receives as input. You can rest assured that your computer vision implementation will perform optimally as it is powered by synthetic data.

Synthetic computer vision: the future of object detection
Considering this is a field of study which has been in the attention of fervent AI researchers since the 1960s, mainstream advances in computer vision have not been as drastic as its lofty expectations. Attempts to democratize the technology for widespread commercial use have been throttled by repeated failure to optimize its largest dependency, the sourcing and preparation of high-quality data.
Approximatively 1% of AI research is focused on sourcing and preparing data for AI models with the other 99% focused on AI model training and algorithm optimization. This is even though the data component of computer vision takes up 80% of a developer’s time when implementing a solution that relies on an AI model while 20% of his or her time is spent on the model itself.
The disconnect between where a developer spends his or her time versus where advances are made in terms of efficiency presents a noticeably huge problem for the future of this type of computer vision. On the other hand it also represents a big opportunity for those who are willing to innovate with a more sophisticated and capable solution.

Neurolabs won the 2nd edition of the "UiPath Automation Awards CEE" startup award. The UiPath Automation Awards recognize the best startups and scaleups across Central Eastern Europe and Turkey that are using software to solve automation challenges.
Co-Founder, Neurolabs
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.