Process Mining Demystified: A Guide to Connecting and Transforming Your Data
Process Mining Demystified: A Guide to Connecting and Transforming Your Data

Summarize:
Introduction
This blog is the first in a series of blogs called Process Mining Demystified. In this series, we cover how users can connect their data to Process Mining, create a dashboard, and effectively analyze their processes.
Data is vitally important as organizations strive to identify pockets of value and efficiency within business processes. With UiPath Process Mining, organizations can leverage their data to gain insights into workflows, identify bottlenecks, and optimize and automate processes.
To maximize Process Mining’s potential, strong data connections are crucial to convert raw data into actionable insights for automation. In this blog post, we'll explore what data engineers and process analysts need to know to connect and transform data for UiPath Process Mining. Let's dive in.
Choose your process
The first decision you need to make is which process to mine. You can start by browsing through the out-of-the-box app templates that are available in UiPath Process Mining. App templates make it easier to connect to common source systems for common processes. For example, purchase-to-pay, order-to-cash, lead-to-order, on systems like SAP, Oracle, Salesforce, and ServiceNow. The full list of available app templates can be found here.
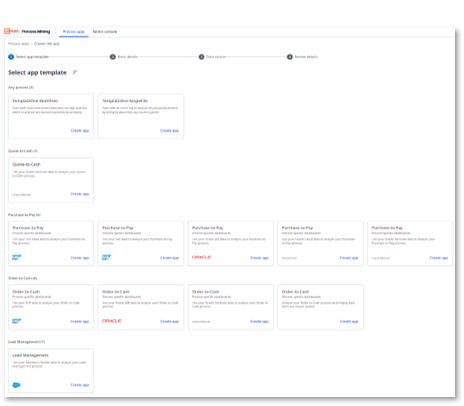
If you’re thinking of a process that’s not in the list of available app templates, then a good candidate for your first project is a process with data stored in a single source system, and more than 100K cases.
Read on to learn how you can create the event log by setting up data transformations.
Setting up an event log
Designing an event log is a fundamental step in the Process Mining journey. Deciding what your most important goals or KPIs are is key to improving your process. Using your strategic goals, you can sketch out the expected process and select which of the activities will lead you to the most critical insights. For each activity, check in which source system the corresponding data is stored. Additionally, think about which business objects are needed for contextual information.
There are a few key considerations when designing an event log:
To get results fast, find the minimal set of activities to start with (ideally all from one source system).
Add more data elements incrementally to enhance the analysis possibilities of the process app. If the process data is stored in multiple systems, they can be added one-by-one.
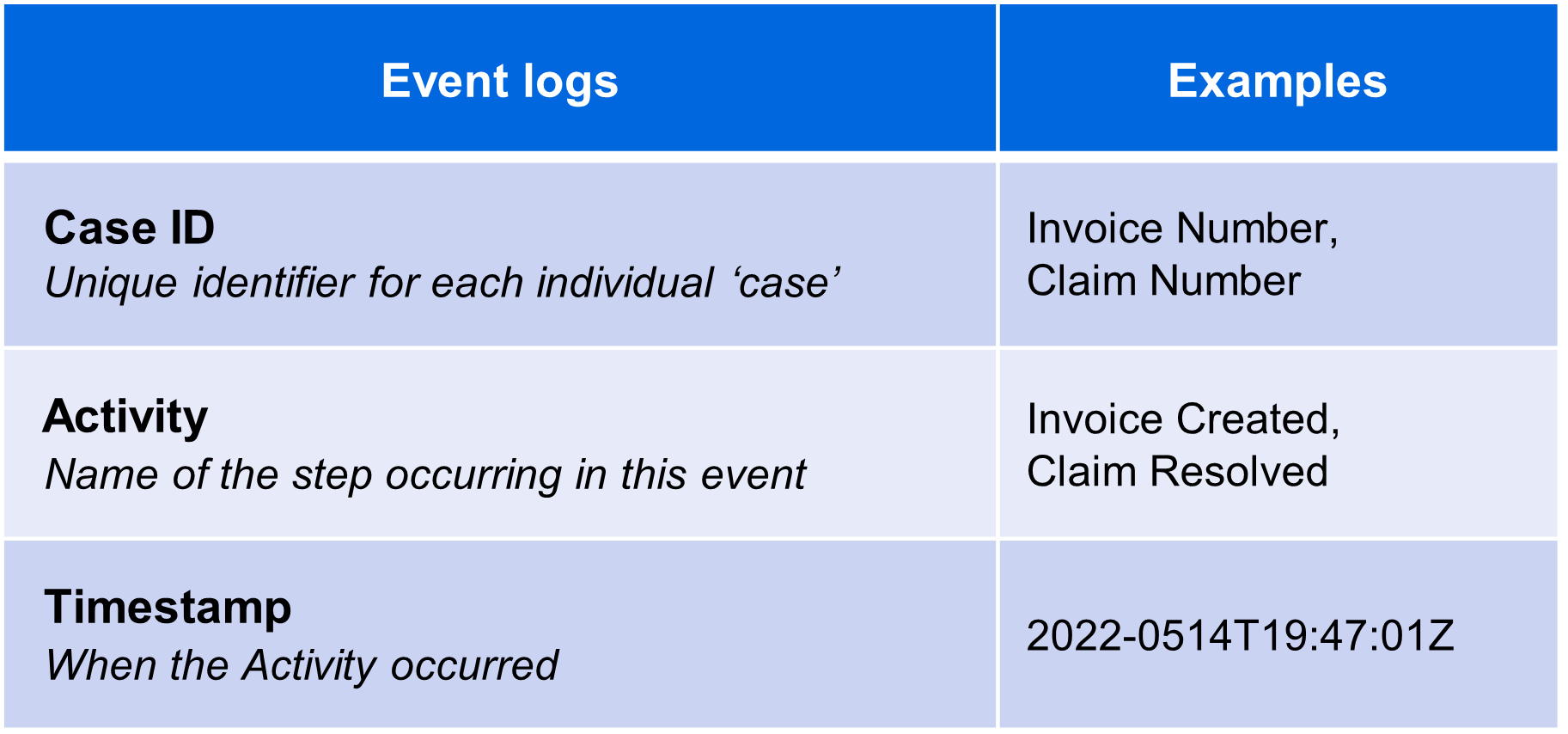
By following the documentation, you can design an event log that accurately captures the sequence of activities, timestamps, case identifiers, and additional contextual information. The event log serves as the foundation for valuable process insights, identifying bottlenecks, and driving process improvements through Process Mining techniques.
Data extractions
Once you have determined which process to mine and the activities you want to load from the given source systems, you can set up your data extractions. For that you need to determine which input data tables are needed for the desired set of activities.
Uploading data can be done in several ways, including:
Uploading files: uploading csv files in the user interface. Teams typically do this in a Process Mining project when working with data exports from a source system.
Using data extractors: with data extractors, you can connect your Process Mining app to load data from source systems directly (provided necessary approvals and access to the source system is arranged).
Often, Process Mining projects start with file exports from source systems. When a process app is published to end users, recurring data refreshes are set up using data extractors.
Data transformations
So, what are transformations? When you create a process app, you want to make sure the data used in the process app accurately reflects your business process. With data transformations written in SQL, you can customize the data used for Process Mining and create your own event log.
As you begin editing data transformations, we strongly recommend that you:
Have in-depth knowledge of SQL—(don’t worry, we’ve got you covered with tips and tricks for writing SQL transformations).
Are familiar with the source system used for data extraction.
Involve the process owners or domain experts—they have the process expertise to help you ensure the process app contains the right information.
Check out the documentation for more info on how to edit the transformations of your app.
Input queries
The first step in setting up your transformations is to define the input queries. These should list the set of tables and fields you want to load from the extracted data, and which data types they have. Specifically, it’s important to make sure that the datetime format in your input data is set properly. Please see the documentation for more information on the structure of transformations.
Entity queries
Next, the business objects that are used in your process should be defined. For example, in a Lead-to-Order process, the typical entity tables would be Lead, Opportunity, and Order. This step usually requires you to join several input tables, and to clean up the data records that shouldn't be loaded. For more information, see the documentation.
Event queries
Then, you need to define a set of events. How you do this depends on the format of your input data. If the format of the input data is a transaction log, then link the data records to your entities.
If the events are captured in the data as timestamp fields, then follow another approach. For example, in case your Lead table contains a “Lead created” field, convert that into separate event records. For each datetime field that should become an event, a new set of records should be created.
Business logic
Finally, it’s time to enrich the data with business logic that you want to use in your data analysis. You can add derived fields in your transformation to calculate business definitions for desired throughput times, deadlines, categorizations, etc. In UiPath Process Mining, you can define a set of tags to mark specific cases with useful properties that you want to monitor. For example “No approval done”, “Goods delivered too late”, “Four eyes principle violated”.
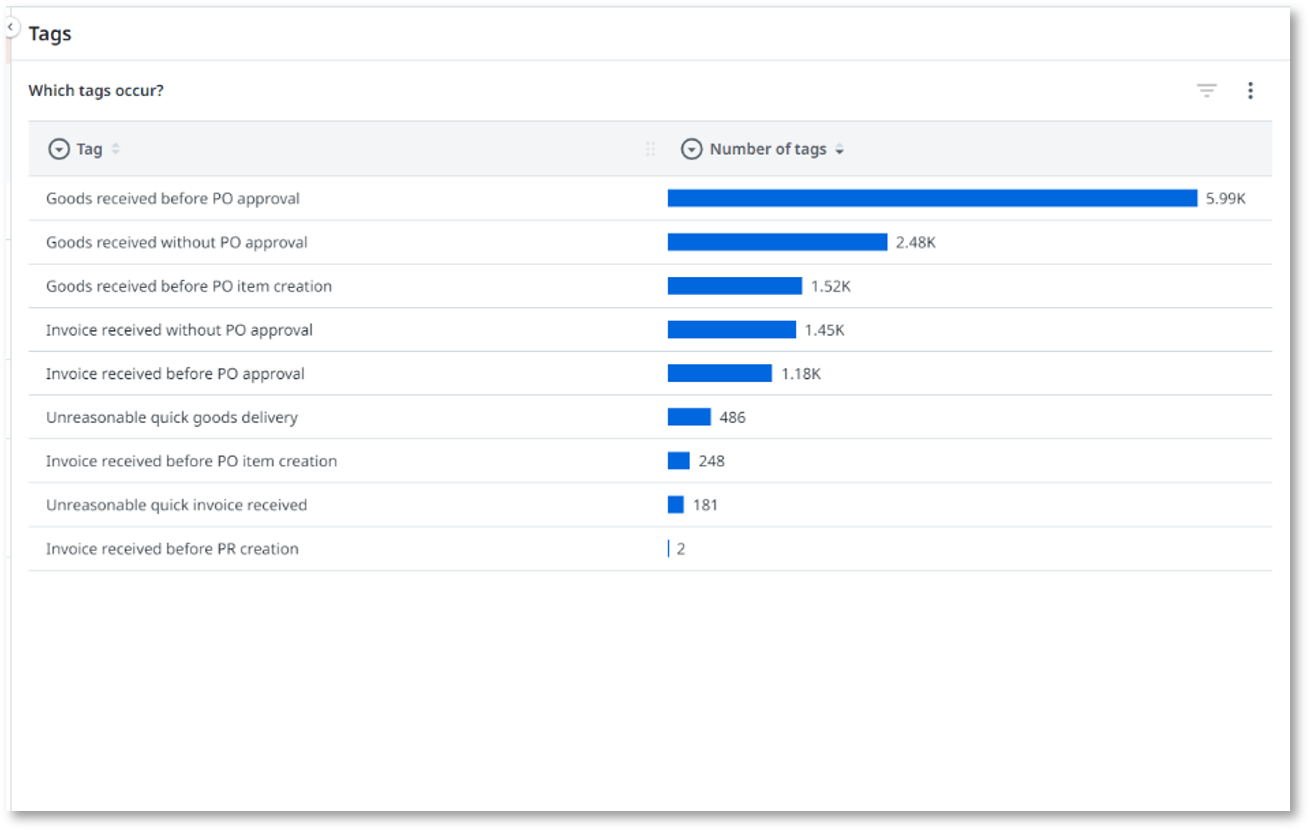
See the documentation for more information on defining business logic.
Transformation output
The output of transformations must match the set of fields expected by the process app. Make sure that your fields have the correct data types, and that the names are provided in the proper cases. If you want to add custom fields to your process apps, you can rename them in the process app, using the data manager.
And then you're ready! Using your custom transformations, you can load the new data into your process app and start Process Mining. From this point on you can iterate and add more data incrementally to gain more insights about your business process.
The smaller the initial dataset, the faster you can get started with Process Mining. So, we always advise putting special care into defining the very minimal dataset required to light up your Process Mining app.
Unlock the power of Process Mining today
Process Mining is a powerful tool for optimizing operations and gaining valuable business insights to automate and improve processes. In this blog post, we discussed the essential steps to connect and transform your data, to provide accurate and impactful results.
Remember the importance of well-designed event logs, iterative data transformation refinement, and documentation for future analyses. By applying these principles, you can begin using Process Mining to begin automating and transforming your business processes.
Happy Mining!
Topics:
Process MiningProduct Management Director, UiPath
Related articles



Get articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.
Get articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.