
Product Sequencing Recommendation Model with UiPath AI Center™
Share at:

Introduction
The world of e-commerce has become increasingly complex as consumers demand faster delivery times and more personalized experiences. Acquiring new customers and maintaining existing ones is one of the biggest challenges for e-commerce platforms. This involves providing a seamless and personalized shopping experience, which requires a deep understanding of the customer’s needs and preferences. This has led to the need for companies to optimize their product sequencing and recommendations to meet customer demands and stay competitive in the market.
To address this demand, recommender systems have become an integral part of e-commerce platforms. They help online businesses to recommend products to their customers based on their browsing and buying history, preferences, and other behavioral patterns. Recommender systems can improve customer satisfaction, increase sales, and enhance the overall customer experience.
In this blog post, I am going to expand on the use case submitted for the UiPath AI Summit 2023, AI Challenge, Efficient Product Sequencing Recommendation Model. We will discuss how to design a recommender system for an e-commerce platform using Python programming languages, various libraries, and UiPath AI Center™ to host the model.
Designing a recommender system
The first step in designing a recommender system is to gather data about the customer's browsing and buying history. This can be achieved by tracking customer behavior on the platform, including the products they view, purchase, and search for.
There are several approaches to building a recommender system.
Content-based filtering uses product features to recommend similar products to the customer based on the characteristics or attributes of the items that the user has shown interest in or consumed in the past. The idea behind content-based filtering is that the system tries to find items that are similar to the items that a user has already shown interest in. To do this, the system uses information about the features or attributes of the items, such as price, color, size, etc.
Collaborative filtering, on the other hand, uses customer behavior data to recommend products that other customers with similar behavior have purchased. The idea behind collaborative filtering is that users who have similar preferences or behavior in the past are likely to have similar preferences in the future. This approach involves analyzing the past interactions or behavior of users to identify patterns and similarities, and then using these patterns to make recommendations to users.
A hybrid approach combines content-based and collaborative filtering to provide more accurate recommendations. For example, a hybrid approach might use customer behavior data to recommend products that other customers with similar behavior have purchased, but also consider the product features to provide more personalized recommendations.
The recommendation model, as described in the use cases is trained on customer proprietary data and involved a core team of data scientists, ML engineers, solution architects and automation professionals.
To build the recommendation model, we are going to use a collaborative filtering approach and implement it using Python programming language. Here is a sample code to generate top five recommendations based on the similarity matrix using cosine similarity function.
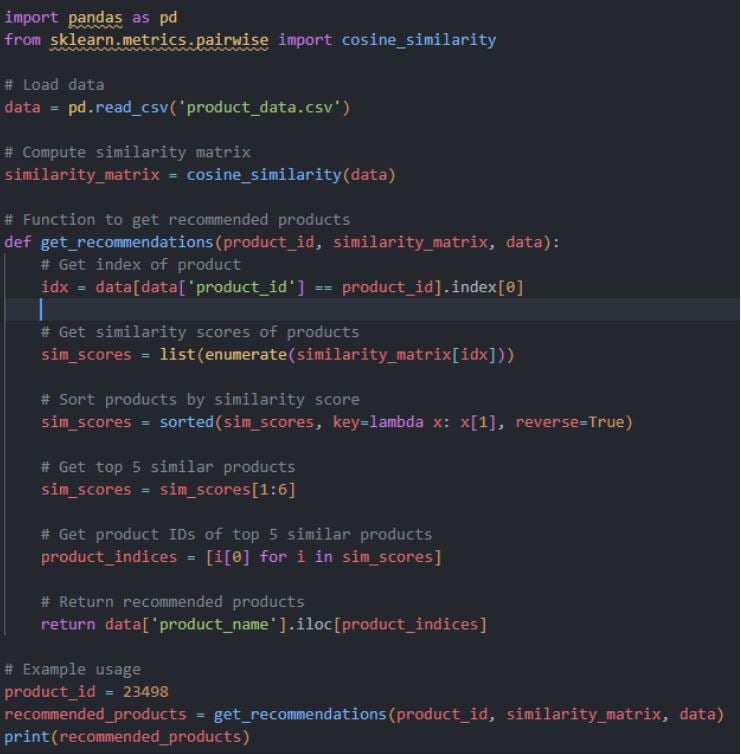
This code assumes that you have a CSV file called "product_data.csv" containing a list of products, customers, and ratings for each of the products. Let’s look at the data and walkthrough an example to understand it better. Here is how the data looks in the source file.
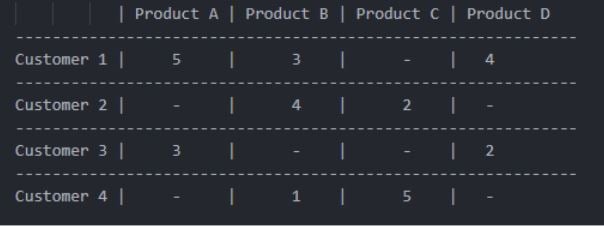
In this example, "-" indicates that a user has not rated or purchased the corresponding product.
Now, to determine which customers have similar interests, we can calculate the similarity between users based on their rating patterns using the cosine similarity function. Let's say we want to find similar users for customer 1. We compare the rating patterns of customer one with other customers:
Similarity (Customer 1, Customer 2) = 0.30 Similarity (Customer 1, Customer 3) = 0.76 Similarity (Customer 1, Customer 4) = 0.63
Based on similarity scores, customer three is the most similar to customer 1, followed by customer four and customer two. Once we have established the similarity matrix for these customers, we can generate recommendations for them. We look at the products that similar users have rated highly, but customer one hasn't purchased it yet. In this case, customer three and customer four have rated the product highly, so we can recommend product A to customer 1. Note that this is just a basic example of a recommendation model. Depending on the specific use case, we need to modify the code to include additional data or use a different similarity metrics. Additionally, you may need to consider factors such as user preferences and feedback to make more personalized recommendations.
Implementing the recommender system with UiPath
Once the recommendation algorithm has been developed, the next step is to deploy the model in UiPath AI Center™. The model needs to be packaged in the following structure for theUiPath AI Center™ to process it for predictions:
ProductSequencingRecommendationModel
ProductSequencingRecommendationModel.sav
main.py
requirements.txt
train.py
main.py contains the primary logic where we need to define a class named as “Main” with the following two functions:
init(self): takes no argument and loads your model and/or local data for the model (e.g. word embeddings).
predict(self, input): a function to be called at model serving time and returning a string.
train.py contains a class called “Main” that implements at least four functions. All the below functions except init, are optional, but limit the type of pipelines that can be run with the corresponding package.
init(self): takes no argument and loads your model and/or data for the model (e.g. word embeddings).
train(self, training_directory): takes as input a directory with arbitrarily structured data, runs all the code necessary to train a model. This function is called whenever a training pipeline is executed.
evaluate(self, evaluation_directory): takes as input a directory with arbitrarily structured data, runs all the code necessary to evaluate a mode, and returns a single score for that evaluation. This function is called whenever an evaluation pipeline is executed.
save(self): takes no argument. This function is called after each call of the train function to persist your model.
processdata(self, inputdirectory): takes an input_directory input with arbitrarily structured data. This function is called whenever a full pipeline is executed.
In the execution of a full pipeline, this function can perform arbitrary data transformations. The result is that it can split data. Specifically, any data saved to the path pointed to by the environment variable trainingdatadirectory is the input to the train function, and any data saved to the path pointed to by the environment variable evaluationdatadirectory is the input to the evaluation function above.
Requirements.txt contains list of packages and dependencies for the model
After the model is loaded into AI Center as an external package with the “Training Enabled” and “Recommend GPU” options turned on to equip the model is configured for retraining with consumer data at a regular frequency. Having GPUs setup for training, speeds up the whole process manyfold. Otherwise, training on huge volumes of data can take far longer with standard CPUs.
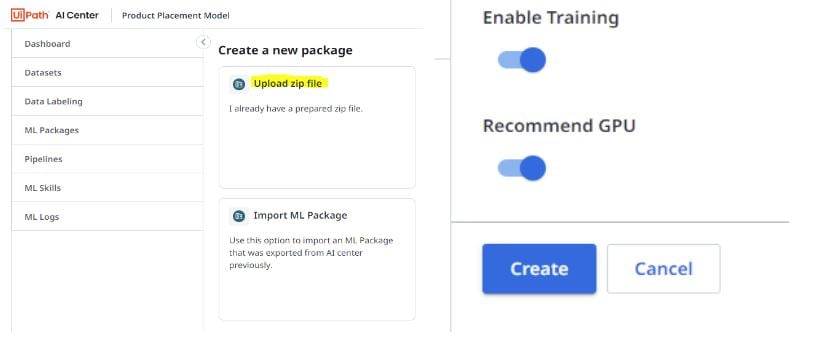
Once the ML package is uploaded and trained, we will expose the ML Skill as a public API. After successful training and deployment, now the model is ready to be consumed via API to start generating recommendations.
Next steps
There are several other AI techniques that can be used to expand this further, such as using neural networks and decision trees, to analyze the data and identify patterns in customer behavior. Natural language processing (NLP) can be used to analyze customer reviews and feedback to identify trends and preferences. Implementing Generative AI model using AI Center connectors can expose further data points to be considered for advanced analytics.
Deep learning techniques, such as convolutional neural networks (CNNs), can be used to analyze product images and identify features that are popular among customers. This can help companies better understand which product features are most important to their customers and use that information to make informed decisions about product sequencing.
Conclusion
In conclusion, designing a recommender system for an e-commerce platform is a powerful way to enhance the customer experience and increase sales. Implementing a recommender system using Python and UiPath can provide a competitive advantage for e-commerce businesses by improving customer satisfaction, increasing sales, and enhancing the overall customer experience.
References
Topics:
AI Center
Chief Technologist, Peraton
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.