
Combining OCR With AI and RPA for Advanced Data Analysis
Share at:

This post was co-authored by Cosmin Nicolae. Nicolae is a Product Manager at UiPath.
Unstructured data is everywhere, hiding in places like documents, audio files, videos, emails, images, and log files — the list goes on. In fact, unstructured data now accounts for roughly 80 to 90% of all data. Yet, despite its abundance and value, unstructured data remains one of the most wasted enterprise resources because companies lack the necessary tools to extract and analyze it.
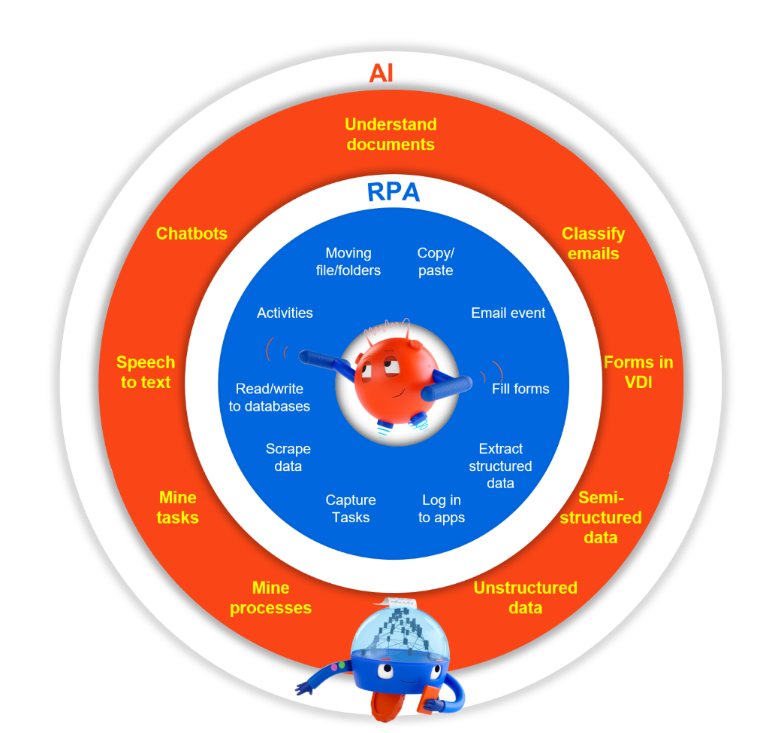
This is changing, as demand is increasing for big data analytics and workflow automation — both of which require structured data. A growing number of businesses are leveraging a technology called optical character recognition (OCR), which makes it possible to convert print or handwritten text into machine-encoded text. As a standalone technology, OCR is somewhat limited (more on that below). Yet, through the trifecta of OCR, Robotic Process Automation (RPA) and artificial intelligence (AI), businesses can enable highly advanced levels of data processing and automation.
OCR is one of the key components within two UiPath solutions:
UiPath Document Understanding allowing automated processing of a wide range of documents
UiPath AI Computer Vision which lets developers automate over virtual desktops and in dynamic interfaces
This blog will provide an overview of OCR while exploring how UiPath is using the technology to enable next-generation data processing and analysis.
First, here is a quick primer on OCR.
OCR: An overview
In layman’s terms, OCR is a process that converts text from images into editable documents.
OCR can reduce and even eliminate manual labor for certain tasks. As a result, it can expedite backend workflows while freeing workers to take on more important responsibilities.
Here are some common ways that businesses are using OCR.
1. Automating data entry
Manual data entry is time-consuming and error prone. By using OCR, businesses can digitize paperwork while minimizing the need for human intervention and increasing the integrity of their data.
2. Editing documents (scanned or PDF)
Employees often receive scanned documents and fax notifications that are not in an editable format. This is common case in departments like finance, supply management, human resources, legal, and compliance. Traditional scanners can only export documents as images or PDFs. For example, you cannot scan a contract or purchase order and then edit it in Microsoft Word or Google Docs. However, utilizing an OCR engine, it is possible to recognize the text and export it to a machine-readable format for further editing and processing.
3. Enabling employees with visual impairment
Employees with visual impairments often need to convert paper documents into digital formats. OCR can help by converting written text into text-to-speech, streamlining the process.
4. Organizing documents
OCR can automatically sort through varied piles of documents and organize them according to specific rules. A classic example would be organizing invoices based on type or vendor. Or in critical processes such as utilizing multiline OCR (MLOCR) in a mail sorting machine that scans addresses and determines how to route mail through the postal system.
5. Understanding text over interfaces
OCR makes it possible to process data over remote interfaces, making it faster and easier for remote teams to collaborate.
The limitations of OCR
While OCR is very powerful, it has several limitations when used as a standalone technology.
Here are some of the top limitations of OCR.
1. OCR can’t understand data on its own
First and foremost, OCR can only digitize text from documents and make it machine readable. OCR cannot understand or interpret data without a complimentary mechanism. As such, OCR is often utilized as a component within a larger, more intelligent solution. To enable true process automation at scale, OCR and RPA are combined with AI.
2. OCR lacks context
OCR systems also lack context. For example, an OCR system may transcribe a word as bail when the actual word is ball. An OCR engine by itself will not have the cognitive ability needed to scan the rest of the sentence to see which word should be used.For this reason, OCR as a standalone technology is highly error prone. It requires a human-in-the-loop component to check entries for accuracy. As a result, OCR by itself lacks optimal value as an automation tool.
3. OCR can’t handle variability
In addition, OCR cannot handle variability in the text or layout of a document, which is a big problem when processing documents that vary in structure.
4. OCR can’t separate documents
Further issues can arise if files need to be separated into documents before inclusion in an automation process or if there is repetition in the index fields or key values of a workflow.
5. OCR is not accurate or scalable
At the end of the day, pure OCR is not accurate or scalable enough for complex and cognitive processes. Enterprises require solutions that are mature and flexible as opposed to components that are limited and error prone.
As you can see, OCR as a standalone technology is not sophisticated enough to support today’s advanced enterprise workflows. Yet, when combined with RPA software and AI, OCR can be an extremely useful tool. The next section will explore how UiPath is using OCR to enable highly accurate automation.
Use Case: OCR in UiPath Document Understanding
UiPath Document Understanding uses RPA and AI to digitize data from documents so that it can be processed and analyzed. Document Understanding can handle both structured and unstructured data, and it works with a variety of objects — like handwriting, tables, checkboxes, and signatures.
Document Understanding grants many benefits, such as accurate and flexible document processing, increased operational efficiency, reduced risk of human error, as well as the end-to-end automation of complex processes.
It should be noted that document understanding technology is not OCR. The fact that the two are one in the same are a common misconception. Rather, document understanding is an advanced technology that utilizes OCR to digitize text in non-digital documents.
One noteworthy distinction is that UiPath decouples OCR from data extraction. Many companies in this space include OCR with extraction. By decoupling the two, UiPath provides greater choice, flexibility, and accuracy as it becomes possible to select a different OCR engine if needed without disrupting what’s happening on the extraction side. It’s also possible to use UiPath OCR public contracts to deploy your own OCR engine if desired.
How Document Understanding uses OCR
OCR comes into play early in the Document Understanding process — immediately after taxonomy is loaded into the workflow and all files and data are defined for extraction.
Document Understanding uses OCR engines to detect and digitize text, making it readable by a robot. From there, documents are classified from specified lists, data is extracted, and — if needed — a human can confirm the extracted data before it is exported to the relevant repository.
UiPath Document Understanding can utilize proprietary UiPath Document OCR, as well as third-party OCR engines to digitize text. Customers can choose the engine that works most accurately for their use case.
As this figure demonstrates, OCR is part of the UiPath Document Understanding framework. Its sole purpose is to make text machine readable.
Use case: OCR in UiPath AI Computer Vision
UiPath AI Computer Vision solves one of the top challenges in RPA, which is automating virtual desktop infrastructure (VDI) like Citrix, VMware, and Microsoft Windows Remote Desktop.
AI Computer Vision enables software robots to see and understand all elements on a computer screen, instead of relying on hidden properties to make decisions. Using AI Computer Vision, businesses and RPA developers can enable automation for VDIs - regardless of framework or operating system.
AI Computer Vision enables automation that include dynamic user interface (UI) elements such as drop down menus and checkboxes; supporting a wide range of interface types. This solution can reduce implementation time when automating virtual machines while increasing the resilience and reliability of automations.
While AI Computer Vision does utilize OCR, it is not used to digitize documents. This is a subtle, but common misconception.
How UiPath AI Computer Vision uses OCR
It’s impossible to automate in virtual environments using standard OCR and RPA because a remote desktop is ultimately just a video feed. Advanced solutions are required to interpret text, and even more importantly, understanding their type and purpose within an interface.
AI Computer Vision utilizes an advanced neural network with a custom screen OCR developed at UiPath over the past several years to analyze a UI over a virtual desktop feed and understand it, as a human would. This solution can easily navigate any available interface, clicking on buttons, but also doing complex interactions like extracting whole tables and interacting with drop down menus.
For element identification, AI Computer Vision uses a text interpretation technique called fuzzy matching. This technique allows UiPath Robots to identify the correct element each time even given OCR results inconsistencies, thus improving the reliability of resulting automations and shortening the development time all together.
Take OCR to the next level with UiPath
As you can see, there is tremendous value in using an AI-based solution that incorporates OCR. UiPath Document Understanding and UiPath Computer Vision tools go far beyond basic OCR, enabling rapid and reliable automation with enterprise scalability—which allows you to unlock the full value of your data, including what’s unstructured or locked behind a VDI.
Here is a chart to help you decide whether Document Understanding or Computer Vision is right for your needs:
Ready to start putting your document data and VDI systems to work?
To begin, register for the UiPath Automation Cloud where you can begin using UiPath Document Understanding and UiPath AI Computer Vision today.
Start your free UiPath Automation Cloud trial to find out how easy it is to leverage your unstructured data to bring more structure and efficiency to your business processes.

Senior Director, Product Management, UiPath
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.