
Learn Robotic Process Automation with RPA Tutorials for Beginners
Share at:

While we've been able to rapidly create and scale the UiPath Enterprise RPA Platform, we understand that the key to advancing automation learning methods and the application of robots lies in sharing quality resources with the community.
As the Robotic Process Automation (RPA) market continues to grow — projections reflect that the industry will be worth $3.1 billion by 2019 and reach $4.9 billion by 2020 — prepared, educated RPA experts are more in demand than ever.
To share our passion for and knowledge of RPA with the UiPath Community, we've created a library of RPA video tutorials for beginners. These lessons provide industry-leading, free resources for our current and future users to help you develop the skills and knowledge to make their RPA journey successful.
No matter what your automation learning goals are, UiPath offers a full suite of resources to help you become an RPA expert including the UiPath RPA Community Forum, RPA Academy, Academic Alliance, and the community edition, a free version of the UiPath software.
In this article, we've summarized our library of RPA tutorial to help beginners become the next generation of RPA rock stars:
Robotic Tutorials for Beginners
Basic Concept Series RPA Tutorial for Beginners
Excel Automation and DataTables
Data Manipulation in RPA Automation
User Interface Automation Tutorial for Beginners
Citrix - Virtual Environment Automation Series
PDF Data Extraction and Automation Tutorial
RPA Project Organization Tutorial for Beginners
Debugging and Exceptions Handling
Agent Assisted Automation and User Events Tutorial
RPA Orchestrator Tutorial for Beginners
1. Basic Concept Series RPA Tutorial for Beginners
Intro to UiPath
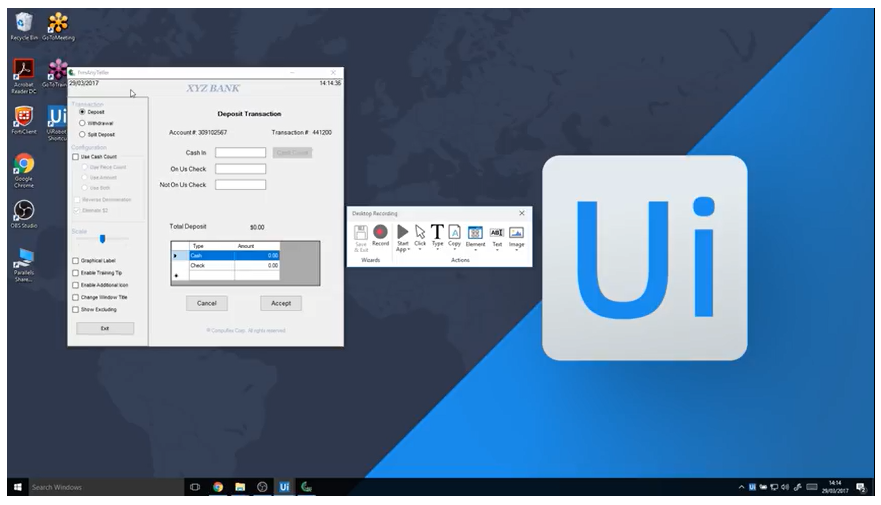
The UiPath Basic Concept Series, the first RPA tutorial for beginners, introduces you to the three main products that make up our RPA platform: UiPath Studio, UiPath Robot, and UiPath Orchestrator.
UiPath Studio is an advanced tool that allows users to design automation processes in a visual way through diagrams. UiPath Robot then executes those processes either unattended (without human supervision) or attended (with a human’s action triggering the process).
This initial tutorial covers the multiple types of workflows and activities available in Studio (sequences, flowcharts, and transactional business processes) to tailor your process to your needs. It also teaches you the basics of recorder functionality, which is often the easiest way to create workflows. Recordings fall into one of four categories: Basic, Desktop, Web, and Citrix.
You’ll also learn variables and .Net functions in order to store values and enhance your automations with functions such as .Trim and .ToString. Additionally, you’ll be introduced to UiPath Executors and Orchestrators, which can interact with many applications at once and coordinate multiple robots.
Finally, you’ll wrap up the lesson with an introduction to assets and queues as well as logs, audit, alerts, and other role management tools.
Activities, Variables, and Data Types
The UiPath Enterprise RPA Platform is your number-one tool for automating your business process.
A background in programming concepts such as variables, if/else decisions, and loops is helpful but not necessary to get the most out of this lesson.
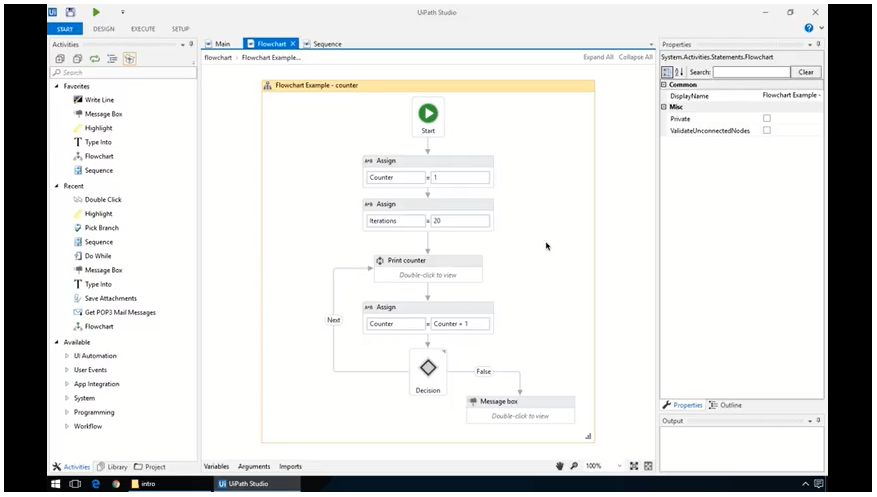
In our Activities, Variables, and Data Types tutorial, you’ll learn about the UiPath Studio interface, particularly the activities and properties panel, workflow designer, flowcharts and sequences, and variable types.
The activities panel holds all the action you need to automate different applications and data processing actions. Additionally, the Studio is where you’ll build your automation, and the properties panel allows you to change the different parameters and settings of your process.
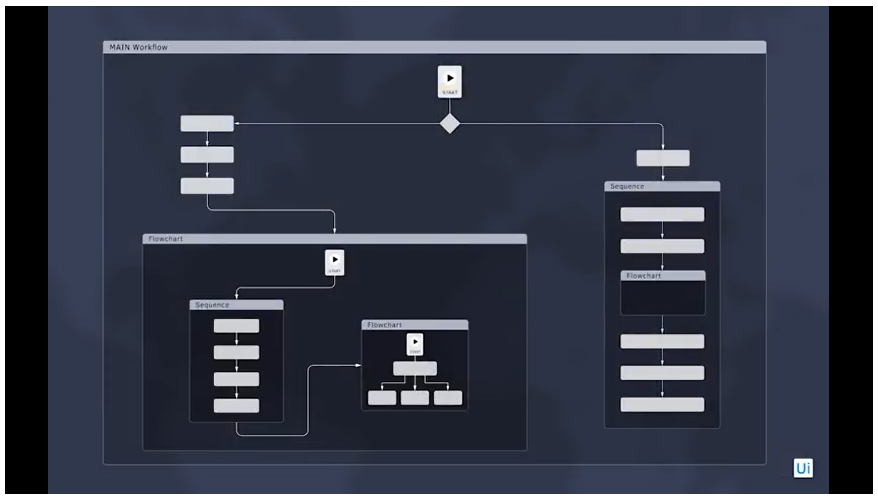
Control Flow
In UiPath, you can dictate the order in which actions take place through the activities you drop into your workflow, If...Else or For Each statements, and carefully placed loops.
Our Control Flow RPA tutorial for beginners is the most detailed of our Basic Concept videos. In this lesson, you’ll learn about mastering “If...Else” and “For Each” statements as well as loops, both of which are important to be aware of when designing particular sequences of actions.
Loops are structures used to automate repetitive tasks. At the simplest level, points are connected in the workflow in the order they occur, stacking on top of each other. Within the main body section, sequences can also be laid out to repeat secondary actions.
2. Excel Automation and DataTables RPA Tutorial for Beginners
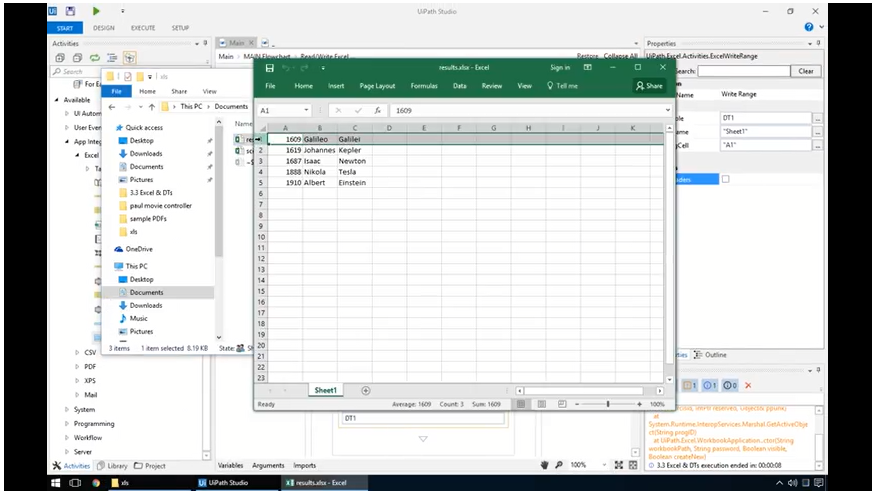
Virtually every business that uses computers depends on standardized document types and communication channels to allow for the efficient exchange of information.
With this RPA tutorial for beginners, we want to make sure that you can quickly get started integrating the most important data inputs and outputs into your RPA workflows.
In our Excel and DataTables Automation tutorial, you'll learn how these tools are used around the world to process and store data, from simple recruiting pipelines to the most complex financial analysis.
This lesson covers Excel application scopes — containers that enable you to work with all other Excel activities. You’ll also learn how to use the most popular Excel activities such as Read Range, Append Range, and Read Cell. Additionally, this video covers popular DataTable activities.
3. Data Manipulation in RPA Automation
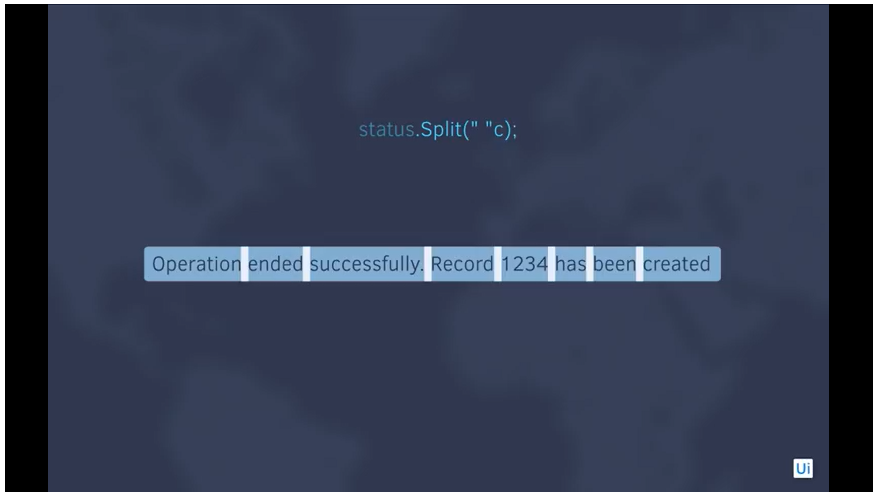
Variables allow you to store all kinds of data through three main types of variables in Studio: scalar, collections, and tables. Understanding the difference between the variable types and their unique applications will enable you to manipulate the information you need to create smooth automation across the board.
Our Data Manipulation tutorial shines a light on the three main types of variable classifications as well as UiPath’s unique GenericValue variable.
You’ll also go beyond the technical elements to learn how to approach organizing automation projects to leverage reliability, efficiency, maintainability, and extensibility when organizing automation projects.
4. User Interface Automation Tutorial for Beginners
RPA bots allow for efficient automation by directly learning from human users and interacting with user interfaces just as humans would.
The UiPath Enterprise RPA Platform allows you to build robots that can easily mimic your processes and actions through screen scraping and recording. Based on the techniques you’ll learn in this RPA beginner tutorial series, your robots can act quickly and directly on the applications you use by identifying the language or images on the screen to trigger action.
Recording
Recording allows you to simply and quickly capture the steps of a process to create a seamless automation that imitates the human process. By mastering the following recorders through our UiPath Recording RPA tutorial for beginners , you’ll learn to expertly mimic your actions with automation:
Basic
Desktop
Web
Simulate Type/Click
Citrix
The tools allow you to create automation for single activities, desktop applications, multiple actions, web apps, and virtualized environments.
The Basic recorder is suited for singular activities, while the more complex Desktop, Web, and Citrix recorders are designed for their respective environments. Additionally, you’ll learn how to use the manual recording for the input and output of data.
Advanced UI Automation
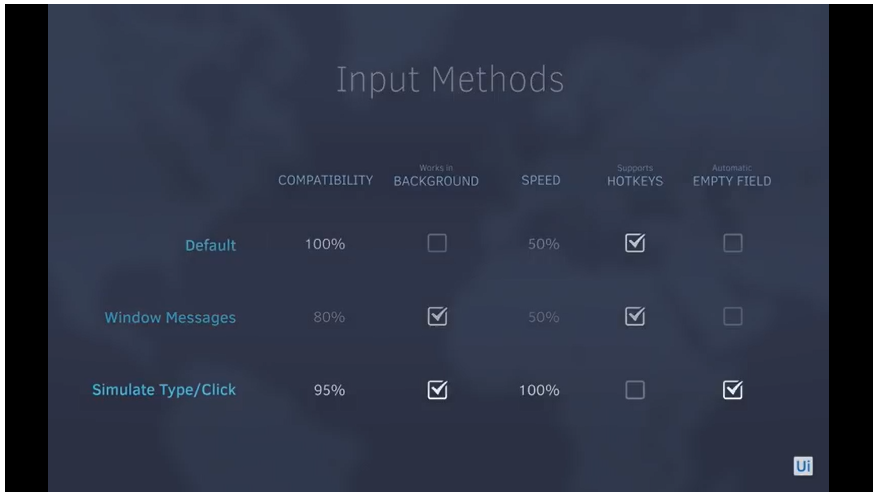
In order to truly master processes that enable your robot to act directly on the applications or web page you’re automating with clicks, typing, shortcuts, and other actions, you must learn the ins and outs of input and output actions.
Input and output functionality allows your robot to operate in the background while quickly and efficiently interfacing with your applications.
The Advanced UI Interaction Tutorial will teach you how to assign actions and control feedback mechanisms via advanced UI automation.
Our tutorial primarily focuses on:
Input methods
Default mouse and keyboard actions
Simulated type/click
Window messages
Output methods
Fulltext
Native
Selectors
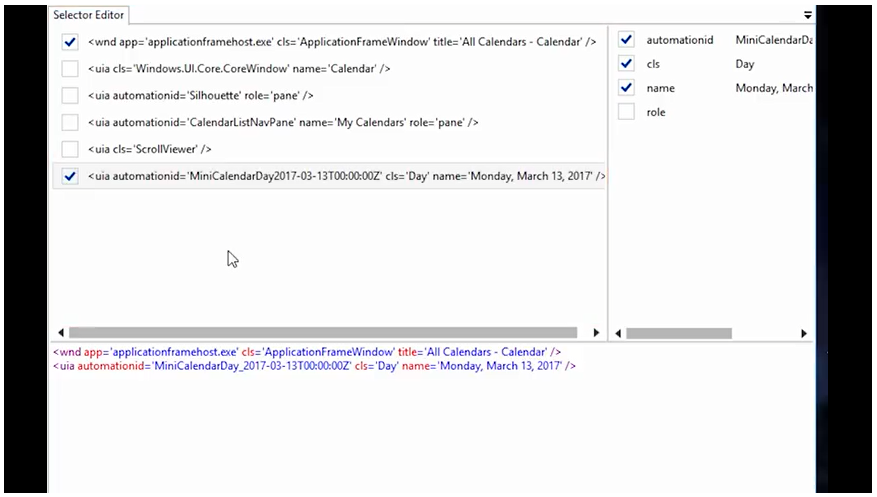
When automating your business processes, you don’t just want robots that are quick, you want ones that are accurate and dependable. Selectors ensure that your finished automation is as reliable as it is proficient.
The Selectors tutorial introduces the basics of how to set up and edit your automation flows without recording, where you have full control over which objects the robot manipulates independent of whether you are targeting website content or offline software.
Selectors store attributes from nested containers---those that User Interfaces (UI) and HTML web pages are built with---in the shape of an XML fragment in order to identify specific triggers and elements from a window or page.
5. Citrix - Virtual Environment Automation Series
These RPA tutorials for beginners will teach you how to manually add actions to your recorded workflow, as well as introduce you to the advanced Citrix automations possible in virtualized environments with UiPath.
Citrix Automation
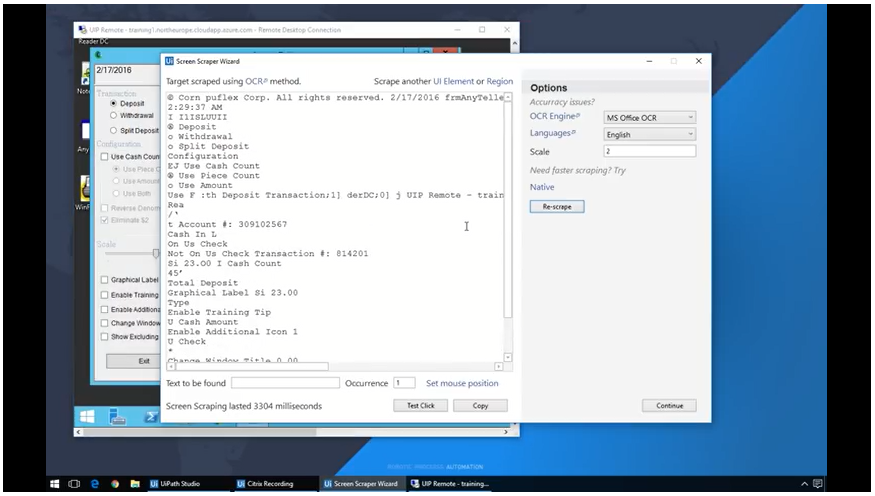
Citrix automation allows you to automate virtualized environments, scrape images, scan the screen of the virtual machine, and extract text.
Our Citrix Automation tutorial provides tips for automating virtual applications, adding actions to already recorded workflows, and retrieving data using the OCR engine.
In this lesson, you’ll learn how to automate virtualized applications using the OCR engine with:
Click Image
Click Text
Select and Copy
Scrape Relative
Advanced Citrix Automation
With Advanced Citrix Automation, you can detect images on the screen and have your robot start a process when it finds a predetermined image on the display.
In the Advanced Citrix Automation tutorial, we cover the automation of workflows that are only triggered once a certain image is detected using the “Find Image” activity. This video tutorial also explains how to use keyboard commands as well as certain parameters for faster automation.
6. PDF Data Extraction and Automation Tutorial
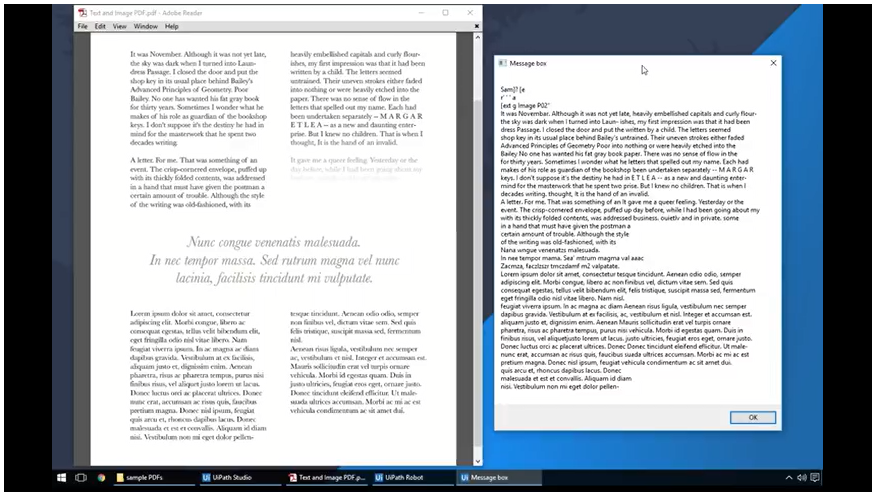
Being able to extract and automate PDF data is a key skill for automation excellence. While there are often predictions that emails will soon become obsolete, emails are still a core business communication channel and an intensely time-consuming activity for many employees.
With RPA, your robot can automatically detect PDFs, extract them from emails, and scrape the screen for the text and specific elements within them.
In the PDF Data Extraction and Automation tutorial, we’ll teach you how to:
Create robots that read PDF text
Use the screen scraping wizard
Extract text from UI elements
Extract changing values from files with the same structure
7. Learning Email Automation
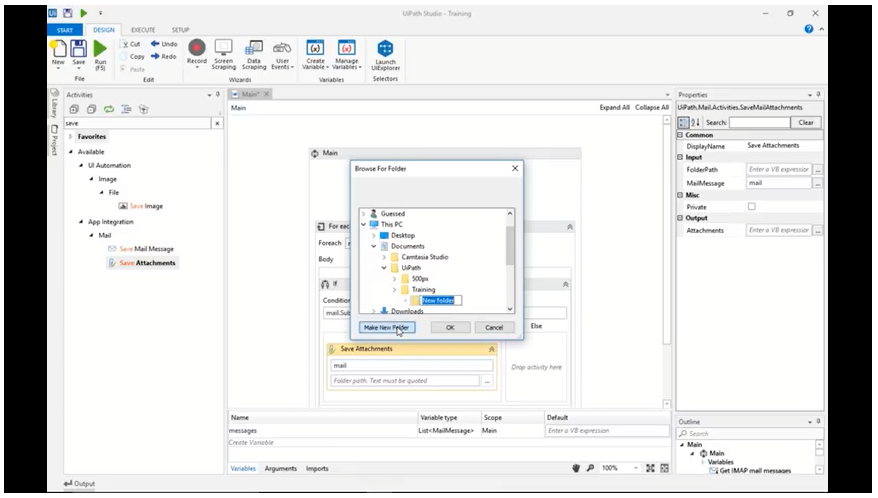
Email automation not only yields very reliable returns, but shows the importance of PDF data extraction. Depending on the email provider your company uses and the process you’re looking to automate, certain email automation options are better than others.
Through the Email Automation tutorial, you’ll learn about the two main situations for email interactions from a RPA perspective:
Input of a process (names, IDs, and attachments being sent in)
Output of a process (reports to managers and alerts for exceptions to a process)
8. RPA Project Organization Tutorial for Beginners

Ensuring RPA success goes beyond just knowing the technical details of building a quality robot. Successful RPA implementation hinges on learning how to maximize your own efficiency and ensure that your robot is:
Reliable
Efficient
Maintainable
Extensible
In our Project Organization tutorial, you’ll learn the best practices for:
picking a layout for each workflow
breaking large processes into smaller steps
handling exceptions
creating readable workflows
keeping processes clean
To better understand a real-world example of automating project organization, you’ll wrap up this RPA lesson with a guide on building a full process with multiple layers.
9. Debugging and Exceptions Handling
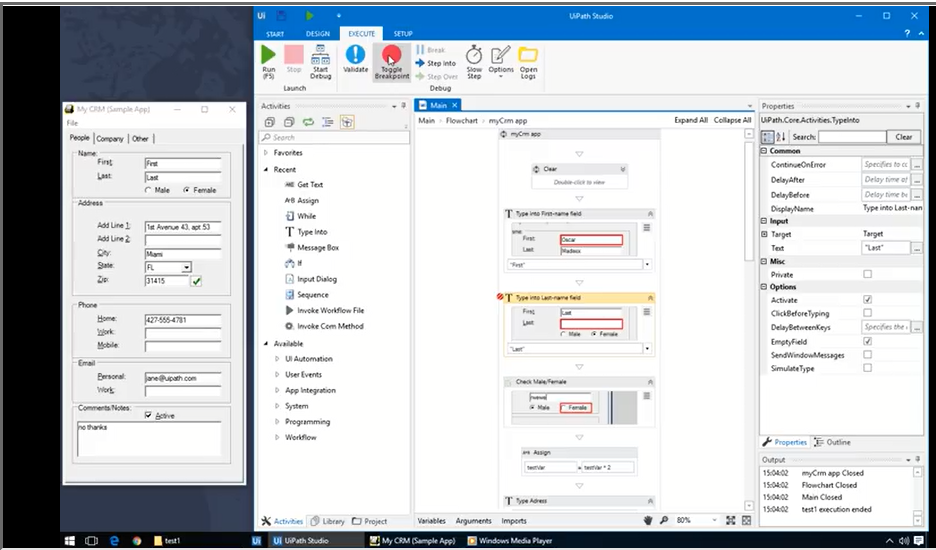
In the early phases of establishing an automated process, your software robots can run into exceptions and require human intervention for debugging.
Luckily, UiPath Studio is enabled with a debug component that helps identify problems easily within complex workflows. Errors are checked for in real-time and detailed by the UiPath Workflow Designer. You can also view a detailed log of exceptions, slow the debugging process, and examine the properties of an active action.
In the Debugging and Exceptions tutorial, you’ll learn the ins and outs of:
checking automated workflow stages
monitoring what data goes into automations
detecting errors in output production
10. Learning SAP Automation
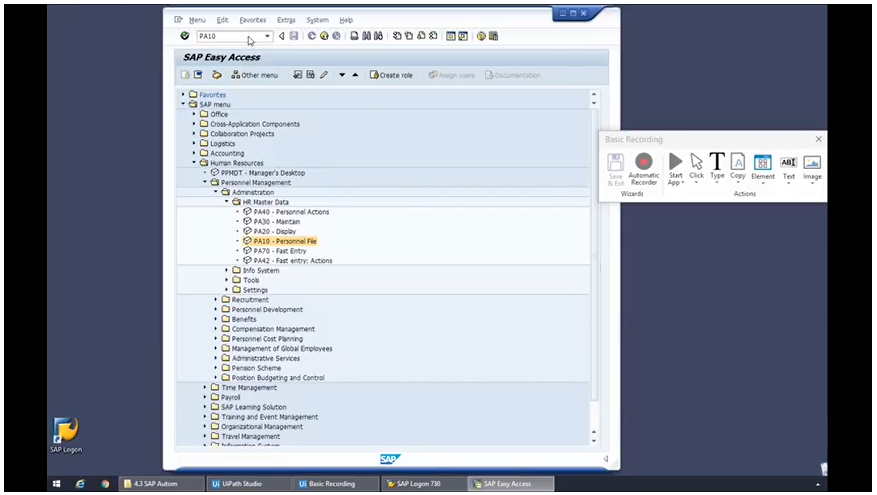
In order to allow for seamless automation with other technology platforms, UiPath has out-of-the-box integration with remote desktop environments and software. One of the most well-known enterprise software used by companies is SAP, and, just like Citrix, it requires specific processes to enable automation.
Our SAP Automation tutorial will empower you to easily use SAP scripting and pick up techniques for recording workflows, configuring activities and keyboard shortcuts, as well as extracting text.
11. Agent Assisted Automation and User Events Tutorial
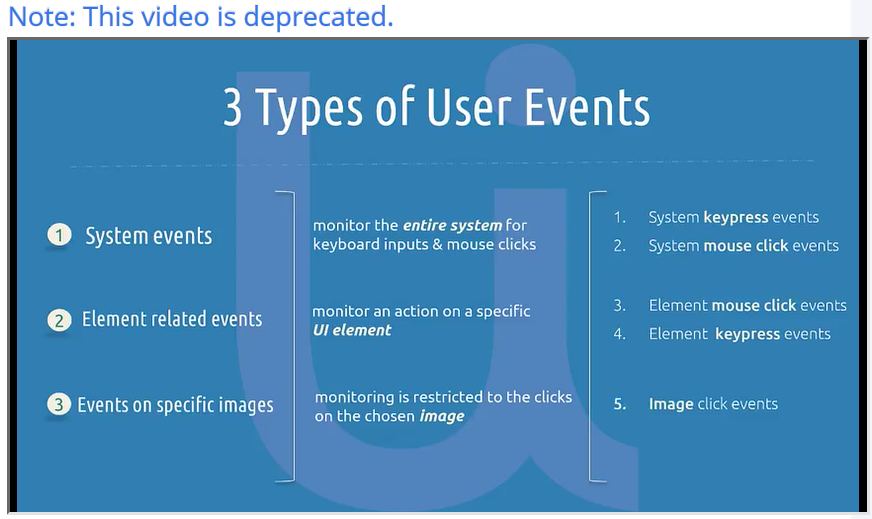
In RPA, two kinds of robots can be built: autonomous, unattended robots and user-assisted, attended ones. Each robot type involves unique automation elements when being set up, but attended robots require additional understanding of user events and user-assisted automation in UiPath.
UiPath's Agent Assisted Automation and User Events tutorial covers the elements unique to attended robots. By the time you complete this lesson, you’ll learn:
System keypress events
System mouse click events
Element mouse click events
Element keypress events
Image click events
12. RPA Orchestrator Tutorial for Beginners
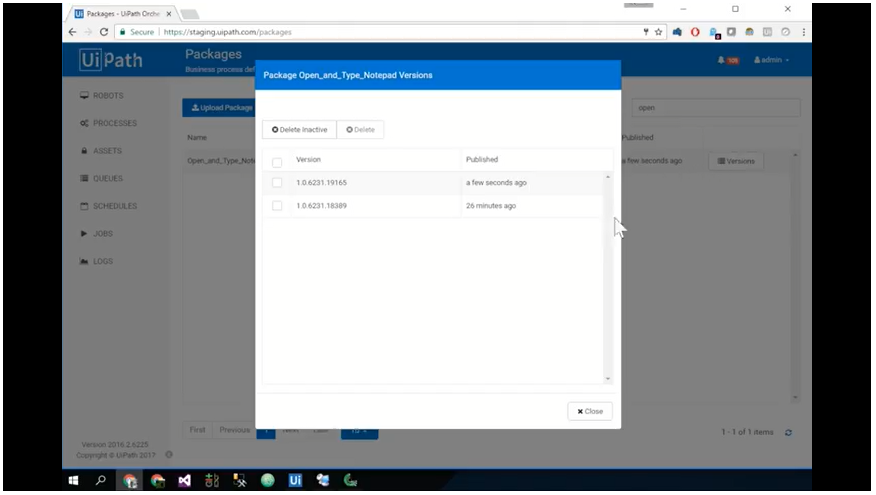
Once your robots are created and assigned processes, you’re faced with the task of how to manage all their actions. Cue the UiPath Orchestrator.
With Orchestrator in command, your robots are controlled, managed, and monitored securely in one place, allowing you to deploy anywhere, scale optimally, and collaborate in privacy.
In the advanced Orchestrator 2016.2 tutorial, you’ll learn about:
Creating, deploying, and monitoring processes
Managing multiple robots
Handling package versions
Employing assets to ease the automation process
Tailoring custom Logs to meet each user’s demands
Using Queues and Schedules
Using Studio activities that affect Orchestrator processes
Start Your RPA Education Journey Today!
It’s no easy task to become an expert in a new technology, and it's no different with RPA. Nonetheless, our detailed video tutorials — many of which contain simple examples that you are encouraged to replicate — allow you to start easily and advance quickly. Automation success is right at your fingertips.
While we take RPA seriously here at UiPath, we aim to make learning RPA easy, efficient, and fun. That's why we've dedicated ourselves to brining high-quality, industry-leading education to the community. Register for UiPath Academy — it’s free!
Learning RPA is fun, and we take it seriously. Register for UiPath Academy, it's free!

Editorial Director, Corporate Blog, UiPath
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.